深度学习框架中的虚拟显存
CUDA和AscendCL都支持虚拟内存管理。两个硬件的API也基本是对齐的,以AscendCL为例,大概需要这么几个API:

CUDA和AscendCL的对应关系如下图:
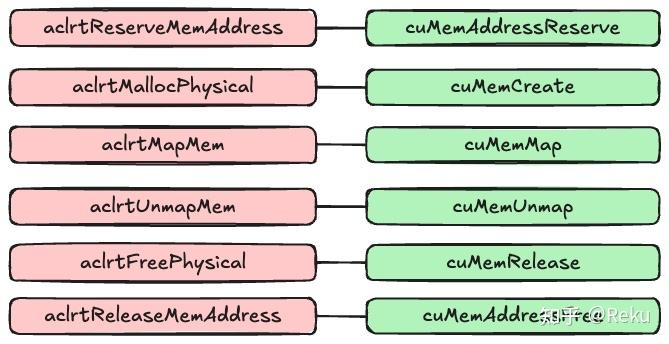
核心就是解耦了虚拟内存和实际的物理内存,实际的物理内存被搞成handle,可以map到提前预留好的虚拟地址,也可以从现成的虚拟地址上面unmap掉。有了这些接口,就可以很方便的实现碎片整理等功能。
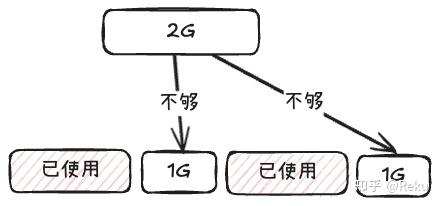
具体而言,例如这样的场景,我们需要申请一个连续的2G的显存,但是显存池中只有两块不连续的1G的显存,在没有虚拟内存这一套接口的时候,只能抛出来OOM(Out Of Memory)这样的报错。
但有了虚拟内存这一套接口,我们就可以让两个1G的虚拟地址对应的handle从这两个虚拟地址上面unmap掉,然后map到一个连续的2G的虚拟地址。
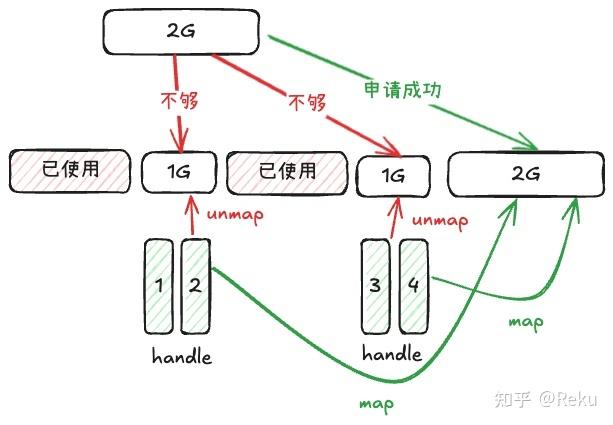
这就是碎片整理,而且不需要框架层做类似传统碎片整理那样的搬运操作。torch里面的expandable_segments,mindspore的VMM,都是这个原理。缺点在于unmap和map这个过程有点慢,而且需要做流同步,需要打断device和host的流水。
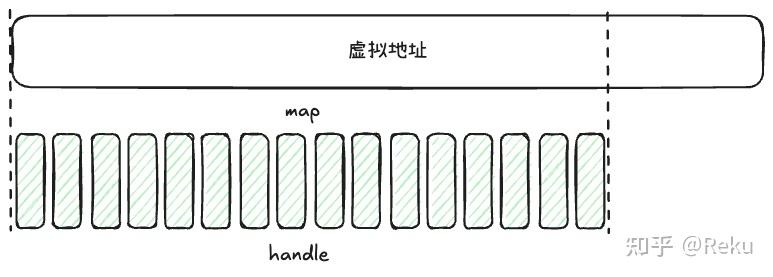
除了碎片整理,其实虚拟内存在显存管理上还有很多帮助。例如现代的深度学习框架,为了方便多个进程使用同一张卡,显存都是慢慢拓展出来的,那最后的显存就会是这种形式:

很显然,不论是cudaMalloc还是aclrtMalloc,都没法保证多次malloc出来的显存是连续的,这就会因为显存的不连续导致碎片。
而虚拟内存就能做到,提前预留好一大块物理地址,不断的申请handle map到当前的物理地址上,这样不管怎么拓展显存,都是一个连续的大块显存。
当然如果有多池子的显存优化(大小显存池、param单独分池子),虚拟显存也可以做到用多少占用多少,不需要提前约定好每个池子占用的大小。而且经过一次碎片整理,不同池子的显存互相复用也会比较方便。(只要不在乎性能)
对于深度学习框架来说,虚拟内存比较好用的点就是这些。其实虚拟内存还有个很大的好处是他可以在虚拟地址(或者叫上层感知到的地址)完全不变的情况下,在底层做一些特殊操作。例如Graph Engine和CUDA Graph这种硬件底层的图调度对于地址使用都有些不可变的约束,如果能够结合虚拟内存,就能玩一些花活。但因为map/unmap这种操作确实代价有点大,一直没有想到一个比较好的整活场景。
vllm sleep mode
最近研究了一下vllm sleep mode的实现,发现他通过虚拟内存的特性,在底层深度学习框架不感知的情况下完成了kvcache/weights的卸载/加载功能。
sleep mode主要是在强化学习共部署的场景下,做完推理之后,得把推理的显存都释放出来给训练用。在没有这个功能的时候,适配强化学习共部署,想卸载kvcache,都是通过objgraph等方式找到所有挂kvcache的python对象,然后一个个把持有kvcache的python对象都干掉,让python对象析构去触发框架显存的释放。跑推理之前还要一个个恢复回来,维护成本很高,每次升级vllm版本还要重新来。
vllm实现sleep mode这个功能,首先是在csrc/cumem_allocator.cpp里面实现了一个简易的显存申请释放的接口,但都是通过虚拟内存的方式进行的。也就是说cumem_allocator里面每申请一块显存,都会包含虚拟地址和底层对应的handle两个信息。这些信息会通过callback记录到python层。
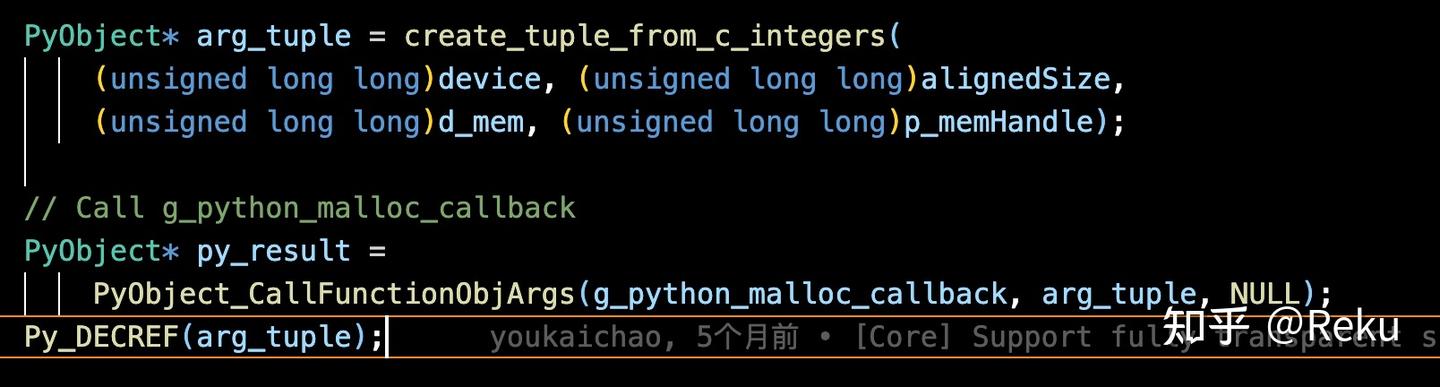
然后在sleep的时候,就申请一个cpu的tensor,把显存里面的内容都拷贝过去。虚拟地址不变,但是虚拟地址下面的handle都unmap并且释放掉。
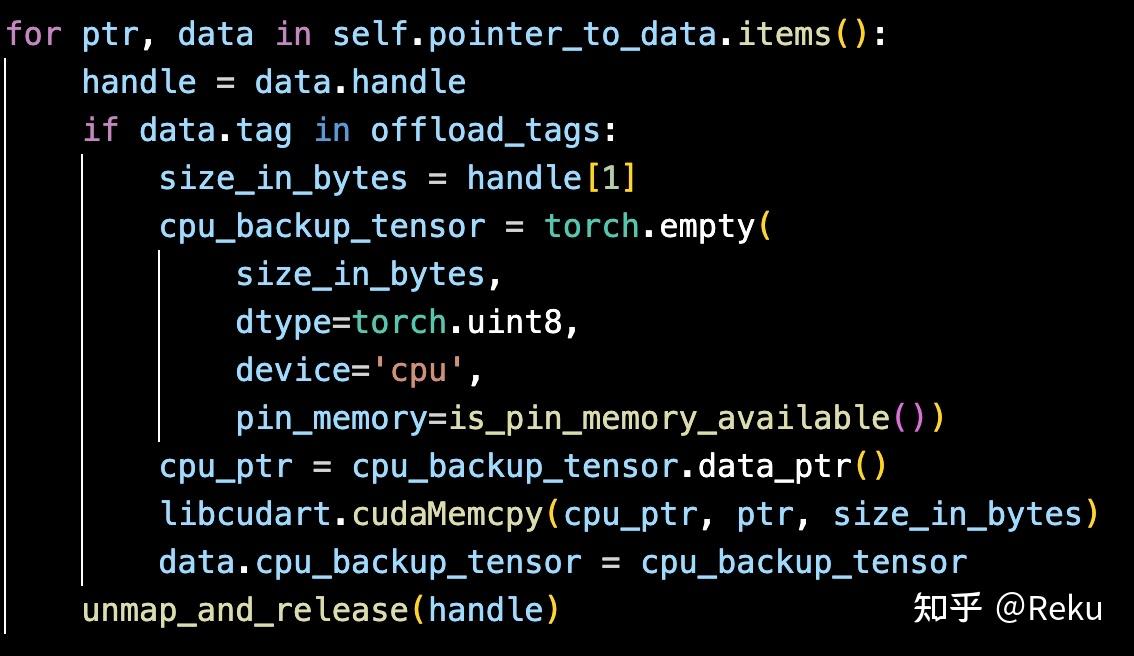
同理wake up的时候,就申请新的handle map到虚拟地址上,然后再把cpu里面的内容拷贝上来。
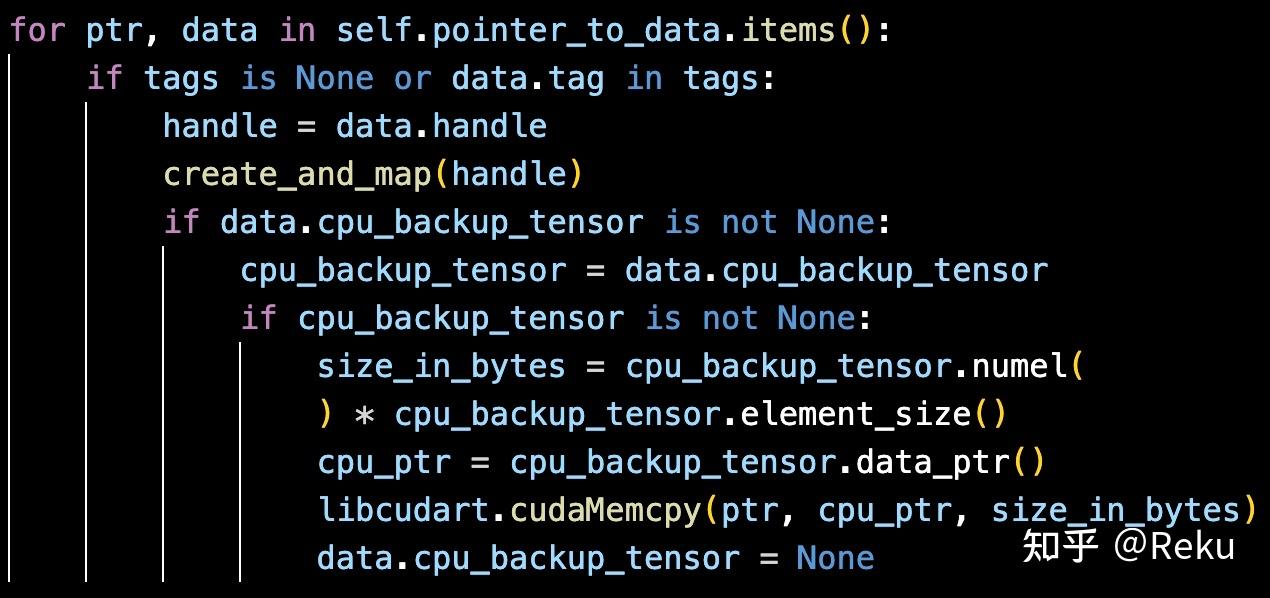
那怎么让torch的显存申请走到cumem_allocator里面呢?vllm的大佬利用了torch外挂显存池的能力,如果在cumem定义的context中,就会自动走到对应cumem_allocator的显存申请流程:
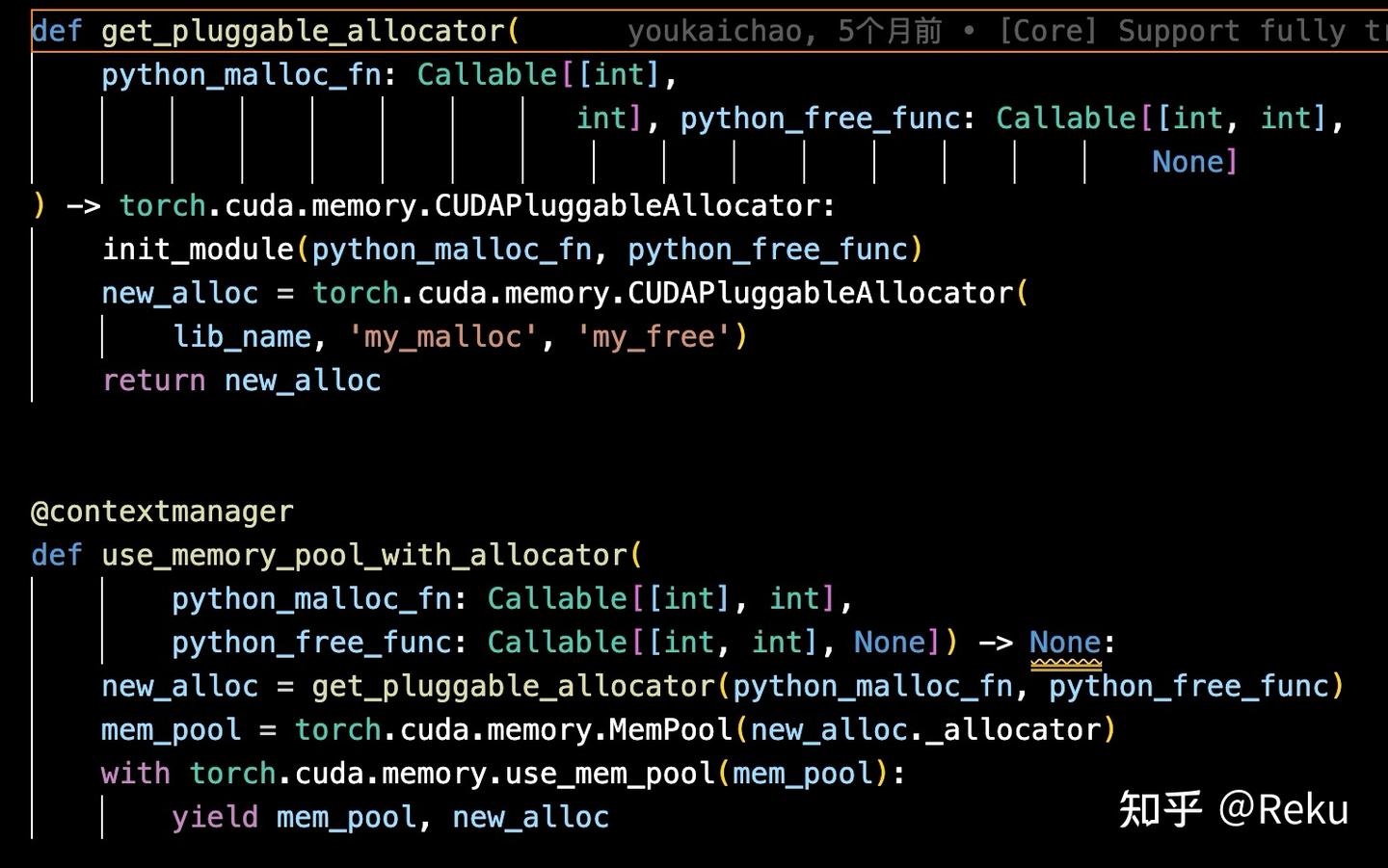
这样只要做好context管理就行了,总比管理python对象的引用关系方便很多:
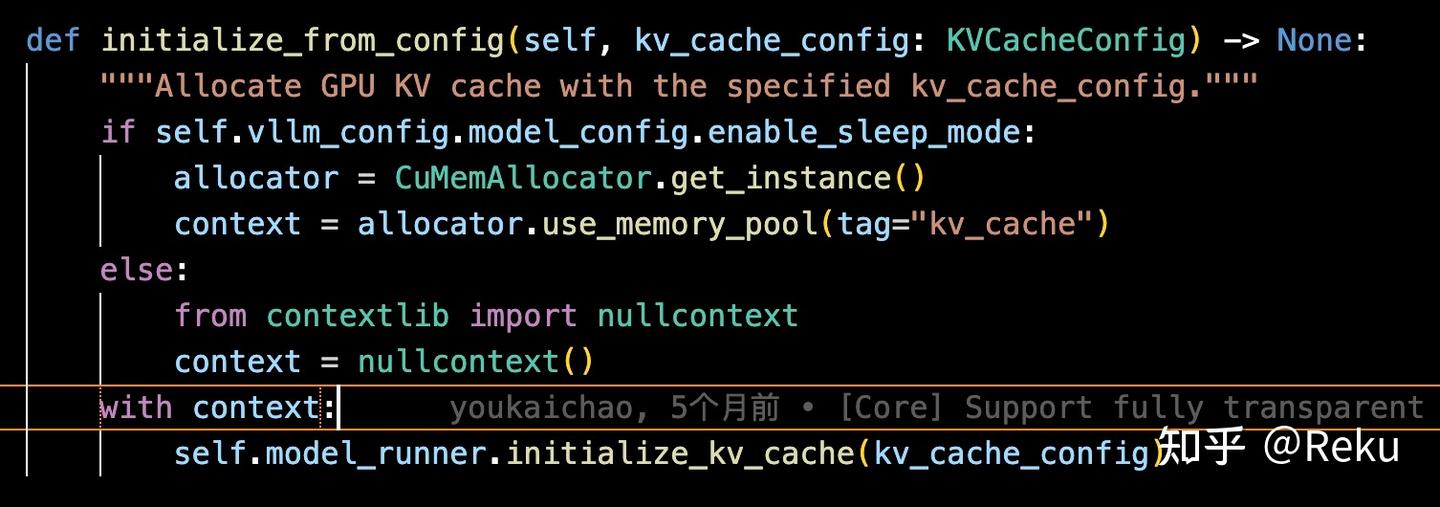
下面来分析,为什么这个东西非常的巧妙。先考虑我如果想实现这个功能会怎么搞?首先做好python对象的管理,然后基于python对象析构去触发显存释放是比较恶心的,也很容易出bug;还有一种方式是能不能把需要释放的tensor都调用一下to('cpu')?但pytorch的tensor to语义不是inplace的。如果想要释放显存需要类似a=a.to('cpu')这样的书写方式,那就和第一种做好python对象的管理一模一样了,没有解决根本的问题。
那我们自己管理显存呢?虽然torch做了外挂显存池的功能,但malloc和free接口都是torch框架来触发的。tensor.data_ptr()可以获取tensor的物理地址,但外部不能修改他。这也很好理解,如果外部能随便改data_ptr,框架的显存管理要怎么做呢?
这时候,虚拟内存的好处就来了。刚刚说虚拟内存还有个很大的好处是他可以在虚拟地址(或者叫上层感知到的地址)完全不变的情况下,在底层做一些特殊操作。vllm sleep mode通过在torch框架完全不感知的情况下,完成了对handle的卸载/加载。torch还以为自己的显存管理的好好的,殊不知在底层已经被偷偷的unmap掉了。vllm社区的大佬水平确实高,这个方案完美结合了torch/虚拟内存的底层各种机制,做到了vllm和torch的解耦。
当然,这套方案也不是完全没缺点,一个主要的缺点就是,因为是对torch框架的隐瞒,torch只要在sleep之后做了任何对这些tensor的读写操作,都会直接触发底层的ERROR,因为虚拟地址并没有映射到对应的物理地址。python的灵活性这么高,这个报错或者校验在vllm层是没法做的。
一个可能的完美解决方案是让torch框架提供inplace to/原地offload这样的语义,这样也不需要做任何python对象的管理,推理框架适配起来也很轻松,报错也能做的非常清晰。问题就是这个语义可能对框架的冲击比较大,对于成图更是重量级:)
从代码注释上看,这个方案也踩中了torch框架的一堆bug,蛮不容易的。比较令人在意的是这个:
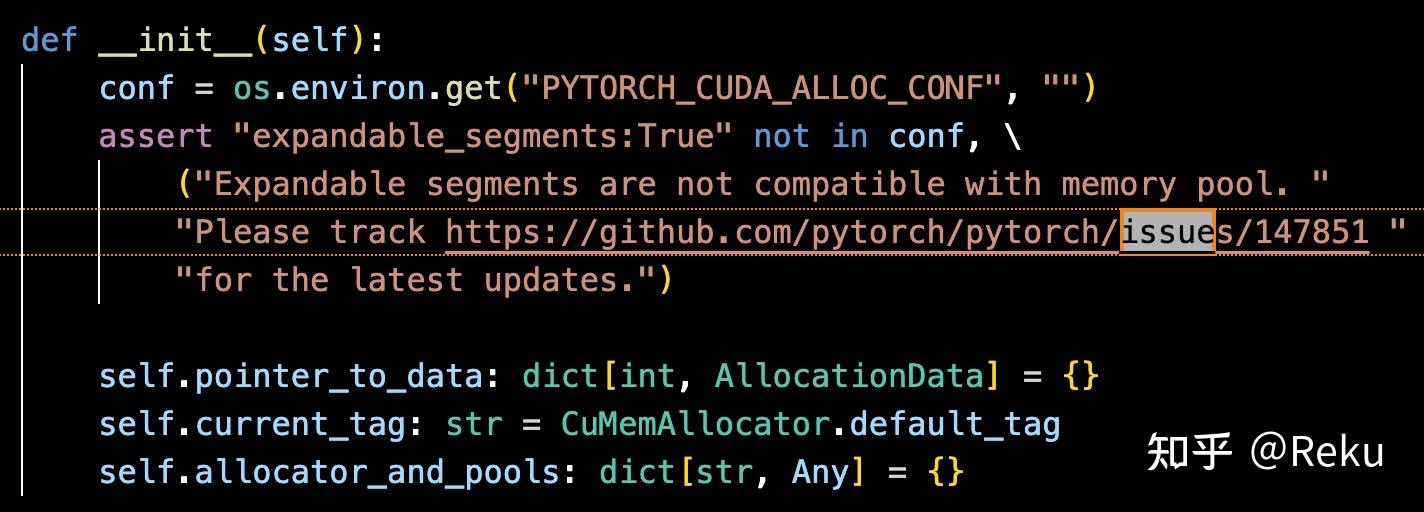
用这个就不能用torch的expandable_segments了,而强化学习场景的load/offload又特别频繁,碎片会比较严重,长稳训练可能会出现一些问题。