工作需要,最近在入门强化学习。这个笔记面向工程老哥们,知道老哥们看不懂数学(因为我就不懂),忽略了大量推导,意会为主。其中可能有些理解错误,望大家多多指正。
LLM中的强化学习定义
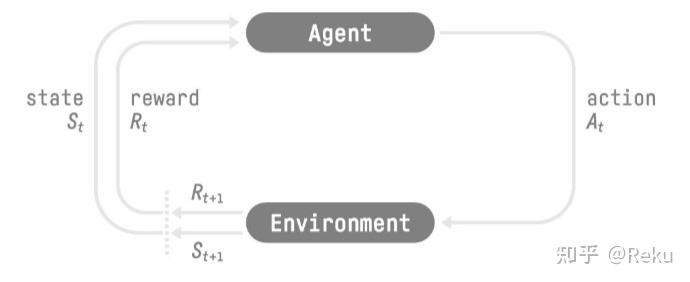
- 智能体(Agent): 经过预训练和SFT的LLM,可以对外界的输入做出回应,有一定的智能。
- 环境(Environment): 其实是整个物理世界。如果是写算法题的话那就是leetcode平台,如果是RLHF的话,就是人类本身。
- 状态(State): 环境的状态,这个东西在LLM RL里面有点模糊,不像游戏AI那么清晰;可以认为LLM之前的所有输出作为环境的状态吗?
- 动作(Action) : 对于LLM来说,就是decode过程中输出的每一个token。
- 奖励(Reward): 就是环境的反馈,比如人类喜不喜欢这个回答或者生成的代码能不能通过leetcode的评测,这里是搞头比较大的地方。
强化学习的基础做法
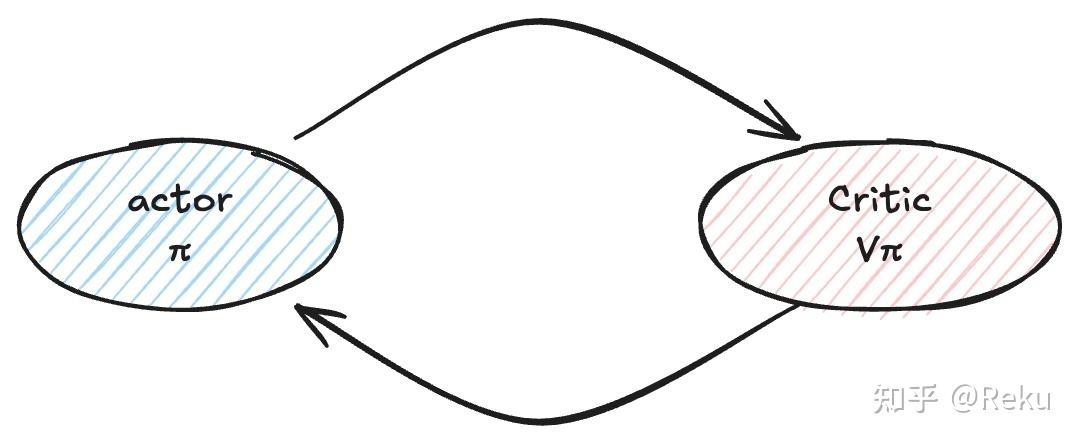
基础的强化学习分成两个角色,actor \(\pi\) 和critic \(V_{\pi}\) 。其中actor代表的就是agent,基于环境的状态和奖励能够做出决策;critic类似教师,基于当前的环境状态和actor的水平,判断一下这个状态的价值。有一点很关键,critic是『因材施教』的,critic的输出一定是针对当前的actor而言的。
既然有两个概念,根据二进制,就有三种对应的做法:
只有critic的实体。如果critic能学的很好的话,很明显,actor只需要看看他的每一个决策critic的反应是什么,选critic反应最好的决策就行(假设action是离散的)。这个方法就叫做value-based,比较典型的是Q-learning。
只有actor的实体。人教人教不会,事教人一下就会。有时候不需要critic,actor只需要和环境做互动,从环境拿反馈就行。这种方法叫做policy-based,就是一般的policy gradient方法。
两个实体都有,两个模型可以互相迭代。critic的学习可能是有偏的,连续的action不好处理(value-based),而直接从环境拿反馈可能方差太大,训练不稳定(policy-based)。所以两个模型互相迭代的方法被广为采用,叫做actor-critic。
actor-critic
数据来源
RL是在LLM的后训练环节,数据是从actor \(\pi\) 采样出来的。因为actor就是要训练的LLM本身,所以这个过程就是给一些prompt,decode出一些回答,基于回答的反馈去更新LLM。
actor的优化
我们先用SFT来理解。如果我们把所有的输入用来做SFT,那所有样本对于LLM都是要学习的。 先写个SFT的梯度:
\[SFT_{\nabla}=\frac{1}{N}\sum_{i=1}^{n}\sum_{t=1}^{T_n-1}\nabla_{\theta}\pi_{\theta}(o_t|q,o_{<t})\]
其中 nn 代表seq数量, \(T_n\) 代表seq长度。这个就是很经典的预测next token的loss。 那强化学习里面要怎么优化actor呢?很简单,就是在每个梯度前面乘上一个reward。
\[Actor_{\nabla}=\frac{1}{N}\sum_{i=1}^{n}\sum_{t=1}^{T_n-1}R(\tau_n)\nabla_{\theta}\pi_{\theta}(o_t|q,o_{<t})\]
其中 \(R(\tau_n)\) 代表的是每个seq对应的reward,这个东西怎么算先按下不表。感性理解就是reward越大,我越希望拟合这个seq;reward是负的,就需要极力避免这个seq。 写成强化学习的符号,就是:
\[Actor_{\nabla}=\frac{1}{N}\sum_{i=1}^{n}\sum_{t=1}^{T_n-1}R(\tau_n)\nabla_{\theta}\pi_{\theta}(a_t|s_t)\]
其中 \(a_t\) 代表action, \(s_t\) 代表状态。就是基于此,我猜想LLM RL中的状态就是之前输出的token,但这个定义其实很古怪,随着交互环境的复杂,后面应该会有变化。
更加泛化一点, \(R(\tau_n)\) 可以定义为 \(A_{\pi}(s_t, a_t)\) ,因为这个奖励和actor本身、当前状态、当前动作都有关系。在很多资料中,这个也被叫做优势函数。
\[Actor_{\nabla}=\frac{1}{N}\sum_{i=1}^{n}\sum_{t=1}^{T_n-1}A_{\pi}(s_t, a_t)\nabla_{\theta}\pi_{\theta}(a_t|s_t)\]
优势函数
\(A_{\pi}(s_t, a_t)\) 怎么算?这个推导涉及到Q-learning,虽然这个推导不算难,但看完感觉工程同学根本没啥学的必要。只需要知道他是通过critic计算出来的:
\[A_{\pi}(s_t, a_t)=r_t+\gamma V_{\pi}(s_{t+1})-V_{\pi}(s_t)\]
其中 \(r_t\) 是当前步骤的反馈,一般是通过reward model计算得来; \(V_{\pi}\) 就是critic模型; \(s_{t+1}\) 是从 \(s_t\) 基于 \(a_t\) 这个东西转移过来的。这个公式其实很直观,我们想一下,怎么让actor满足crtiic的需求?当然就是找到一个 \(a_t\) ,使得转移过去的 \(s_{t+1}\) 尽可能的好。
critic的优化
接上面的逻辑,对于一个完美的 \(V_{\pi}\) ,他的递推式子就应该是(但和上面的东西结合起来有点怪异,actor需要讨好critic,但是critic又要尽量客观):
\[V_{\pi}(s_t)=r_t+\gamma V_{\pi}(s_{t+1})\]
为什么有个 \(\gamma\) ,因为后续状态对前面的影响应该是越来越小的,这个也比较直观。 那critic的loss就天然应该是一个MSE:
\[Critic_{loss}=(r_t+\gamma V_{\pi}(s_{t+1})-V_{\pi}(s_t))^2\]
PPO
actor-critic的主要问题是,每次需要actor \(\pi\) 去做采样,然后再回头更新出新的 \(\pi^*\) ,再用 \(\pi^*\) 去采样,循环往复。这个方法叫做on-policy。
采样后要计算reward function、要计算ref model,这些都挺慢的。很容易就想到能不能采一次样,后面多迭代几轮,利用好之前的采样信息。这种方法就叫做off-policy。
重要性采样
off-policy的核心问题是,之前采样的 \(\pi\) 和训练的 \(\pi^*\) 分布是不同的,数学原理上难以保证训练的有效性。从某个分布采样的数据对另一个分布做训练,有个解决方法叫做重要性采样。数学原理很多地方都有,这里就不加赘述了,直接给出带重要性采样的更新公式,只是给之前的actor梯度加了一项:
\[Actor_{\nabla}=\frac{1}{N}\sum_{i=1}^{n}\sum_{t=1}^{T_n-1}\frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta old}(a_t|s_t)}A_{\pi}(s_t, a_t)\nabla_{\theta}\pi_{\theta}(a_t|s_t)\]
GAE
再回头看优势函数,我们之前的优势函数 \(A_{\pi}(s_t, a_t)\) 是完全依赖 \(V_{\pi}\) 的,但训练的初期 \(V_{\pi}\) 一定是非常不准的。 \(A^{GAE}_{\pi}(s_t, a_t)\) 就是平衡了 \(V_{\pi}\) 的重要性和之后所有 \(r_t\) 的重要性:
\[A^{GAE}_{\pi}(s_t, a_t)=\sum_{l=0}^{\infty}(\gamma\lambda)^l\delta_{t+l}\]
其中:
\[\delta_{t}=r_t+\gamma V_{\pi}(s_{t+1})-V_{\pi}(s_t)\]
可以很容易看出来 \(\lambda=0\) 就是原来的 \(A_{\pi}(s_t, a_t)\) 。如果 \(\lambda=1\) ,那就是 \(-V_{\pi}(s_t)+\sum_{l=0}^{\infty}\gamma^lr_{t+l}\) (可以展开几项写一写)。 \(\lambda\) 的取值代表有多少后续的 \(r_{t+l}\) 对优势函数产生了影响。
裁切设计
上面的两个内容都不难理解,结合起来,actor的梯度应该是:
\[Actor_{\nabla}=\frac{1}{N}\sum_{i=1}^{n}\sum_{t=1}^{T_n-1}\frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta old}(a_t|s_t)}A^{GAE}_{\pi}(s_t, a_t)\nabla_{\theta}\pi_{\theta}(a_t|s_t)\]
但通常来讲,PPO的loss形式都看起来很复杂,这是因为在更新的时候 \(\pi_{\theta}\) 和 \(\pi_{\theta old}\) 的差距不能太大,需要各种方式去限制两个分布的差异。效果最好的是对梯度进行裁切,如果两个分布偏差过大的话,直接加个裁切,不让他们更新的太远:
\[Actor_{\nabla}=\frac{1}{N}\sum_{i=1}^{n}\sum_{t=1}^{T_n-1}min[\frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta old}(a_t|s_t)}A^{GAE}_{\pi}(s_t, a_t), clip(\frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta old}(a_t|s_t)}, 1 - \epsilon, 1 + \epsilon)A^{GAE}_{\pi}(s_t, a_t)]\nabla_{\theta}\pi_{\theta}(a_t|s_t)\]
对于这个裁切的理解,下面的参考资料里面(李宏毅老师公开课和猛猿大神的文章)有基于折线图的很出色的解释,可以参考一下。
上面说critic是『因材施教』的,critic的输出一定是针对当前的actor而言的,所以在actor更新的过程中,critic也要跟着更新。回忆一下之前的critic loss:
\[Critic_{loss}=(r_t+\gamma V_{\pi}(s_{t+1})-V_{\pi}(s_t))^2\]
在PPO中,给这地方增加了一项:
\[Critic_{loss}=(r_t+\gamma V_{\pi}(s_{t+1})+\gamma\lambda A^{GAE}_{t+1}-V_{\pi}(s_t))^2\]
我没怎么明白为什么,可能是为了增大 \(r_t\) 的影响力。左边的 \(r_t+\gamma V_{\pi}(s_{t+1})+\gamma\lambda A^{GAE}_{t+1}\) 我们简写为 \(R_t\) ,这里 \(R_t\) 都是提前算好的,所以用的 \(V_{\pi}\) 都是 \(V_{\pi}^{old}\) 。类似的,PPO也不希望 \(V_{\pi}^{new}\) 和 \(V_{\pi}^{old}\) 离得太远,所以最后也加了个裁切:
\[Critic_{loss}=max([(V^{new}_{\pi}-R_t)^2, (clip(V^{new}_{\pi}, V^{old}_{\pi}-\epsilon, V^{old}_{\pi}+\epsilon)-R_t)^2])\]
ref model
在LLM RL中,ref model是一个有点特殊的设计,之前RL提的不怎么多。主要目的是不让actor跑的太偏,依然保留一些之前预训练获得的能力。ref model和actor的初始化权重相同,一般训练很多步再更新一下权重或者根本不更新。在计算actor loss的时候,增加一项(比如KL散度),不让ref model和actor偏离的太远。
GRPO
GRPO因为deepseek成为了现在最火爆的强化学习算法。AIQL大神的回答里有个神图:
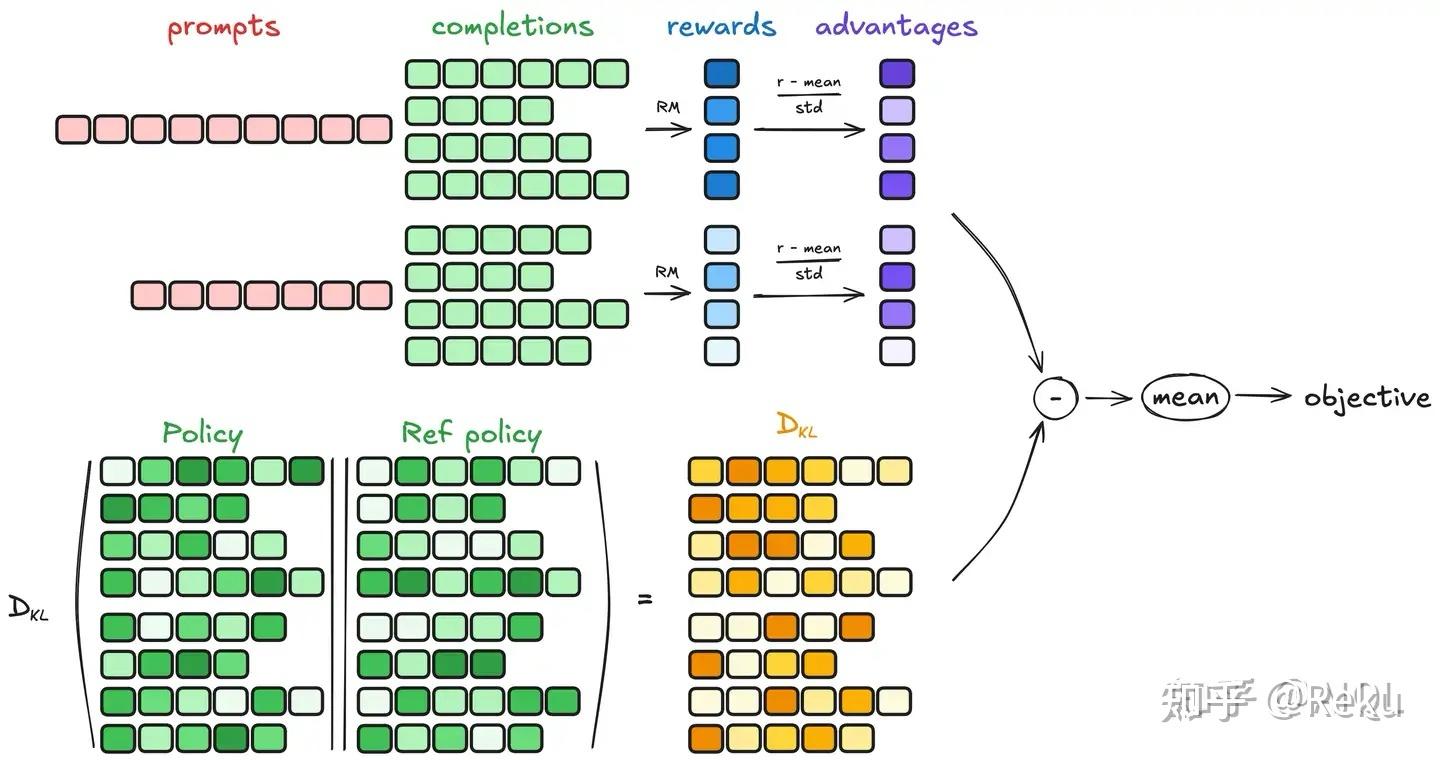
GRPO最核心的点有两个:
干掉了critic model,直接通过一条prompt rollout一堆回复来采样数据集。通过增大采样来抵消方差。
reward model也做了改动。对于很多问题,token level的奖励是不够合理的,DeepSeekMath引入了过程监督。DeepSeek-r1更是直接改成了rule-base。
GRPO是对PPO算法的简化。之前的PPO训练模型中有actor推理、actor训练、critic、ref、reward 5个模型(因为训练和推理需要用不同的框架来加速,策略一般也不同)。GRPO一下子把critic和reward全干掉了,大力出奇迹。其实很多人在复现GRPO的过程中表示和ref model的对齐会影响效果,去掉ref model反而出来深度思考的过程了。那是不是可以幻想一下,以后只需要actor推理、actor训练,actor就和环境做互动就行了?大道至简。
下一篇文章会分析一下当前业界比较优秀的RL框架(openrlhf/verl/chatlearn),结合代码再深入理解一下LLM RL的细节。