个人学习记录。这三个东西本质的原理都差不多,就是attention怎么沿着序列维度切。
online softmax
回顾一下最初的attention:
\(O=softmax(QK^T)V\)
先不考虑融合算子,对于原始的数学公式来说就是两次matmul+一次softmax。matul是最容易优化的,因为良好的数学定义,这个东西可以横着切也可以竖着切也可以分成一小块一小块的,无论是算子优化还是做分布式切分(其实算子优化就是在device内做并行,分布式切分就是在device间做并行),都非常方便。
但是softmax就比较麻烦:
\[softmax(x_i)=\frac{e^{x_i-m}}{\sum^{N}_{j=1}e^{x_j-m}},m=\underset{1\leq i \leq N}{\max}(x_j)\]
如果用最naive的方式去算softmax,需要遍历三遍。第一次遍历求一下m,第二次遍历把分母求出来,第三次把每个元素求出来。如果基于这个计算模式去做分布式,整个的效率会特别的低。因为每次遍历都需要拿到整个N^2大小的矩阵,对于算子来说会频繁的做IO,对于分布式就是频繁的通信。
但指数函数有个很棒的性质,可以只遍历一次数据,就同时得到m和分母:
\[e^{x_j-m_{i-1}}e^{m_{i-1}-m_i}=e^{x_j-m_{i-1}+m_{i-1}-m_i}=e^{x_j-m_i}\]
通过上面的式子,不停的基于新元素,更新分母和m即可。
不仅如此,我们也基于这个性质把softmax分成两块去计算,用到的符号如下:
\(A_l\) 左边一半的softmax分子,\(A_r\) 右边一半的softmax分子,都是个向量
\(B_l\) 左边一半的softmax分母,\(B_r\) 右边一半的softmax分母,都是个数值
\(m_l\) 左边一半的最大 xx ,\(m_r\) 右边一半的最大 xx,很容易得到全局 xx 的最大值 mm
\[softmax_{全局}=\frac{A_{全局}}{B_{全局}}=\frac{[e^{m_l-m}A_l,e^{m_r-m}A_r]}{e^{m_l-m}B_l+e^{m_r-m}B_r}\]
通过这种方式,打开了softmax的并行空间。
online attention
再回头看attention的公式,实际上他的物理意义在于基于QK矩阵乘的值,对V的每一列做一下线性组合。
\[O=softmax(QK^T)V\]
把线性组合展开一下,对于O的每一行来说:
\[o=\sum_{i=1}^{N}(\frac{e^{x_i-m}}{\sum^{N}_{j=1}e^{x_j-m}} \times v_i)\]
把这一步也分成两块:
\[o_l=\frac{A_l\cdot v_l}{B_l},o_r=\frac{A_r \cdot v_r}{B_r}\]
左右两边合并的方式如下,符号含义和softmax的合并一致:
\[o=\frac{B_le^{m_l-m}o_l+B_re^{m_r-m}o_r}{B_le^{m_l-m}+B_re^{m_r-m}}\]
结合上面softmax的并行方式,整个attention的计算也可以像matmul一样做纵向的切分了。
再对着图理解一下,切Q的话,相对容易:
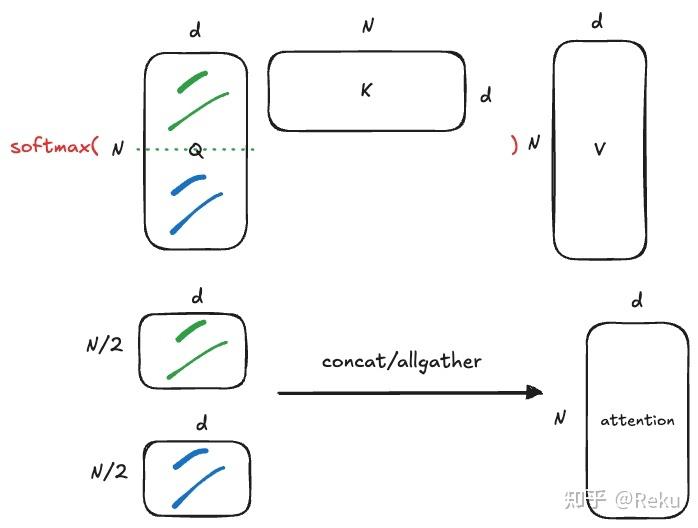
切KV,经过我们上面的推导,也是可以合并起来的:
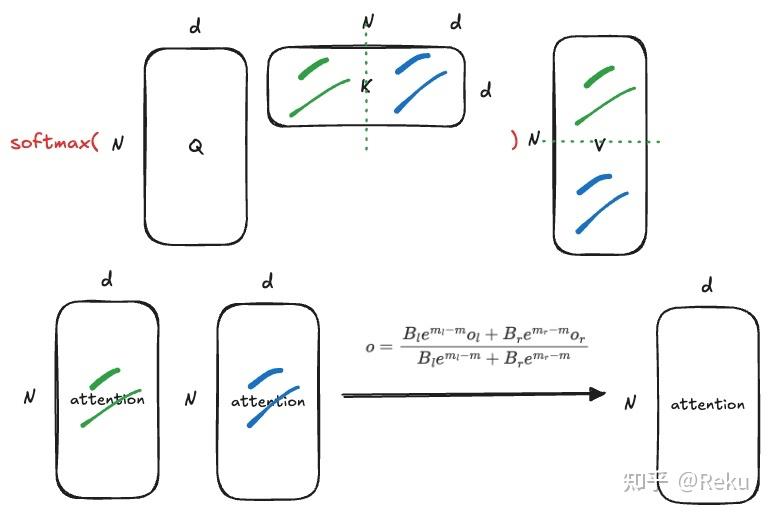
RingAttention/FlashAttention正是基于上面的机制,实现了attention算子的device内并行和device间并行:
device间的并行可以减少N(seq长度)对于训练的限制,将训练拓展到更长的序列上去。对于RA来说,不同设备分别做一下seq切分后的attention,然后通过send/recv,在下一个卡上完成对上一个attention的合并。
对于FA来说,就是利用切块去减小仿存,从而拿到融合算子的性能收益。
这里突然想到一个手撕代码题,用线段树做区间softmax/attention,想用的大哥找我交一下版权费:)
序列并行
说混合序列并行前,需要先了解一下Megatron和DeepSpeed两大巨头最开始是怎么做序列并行的。
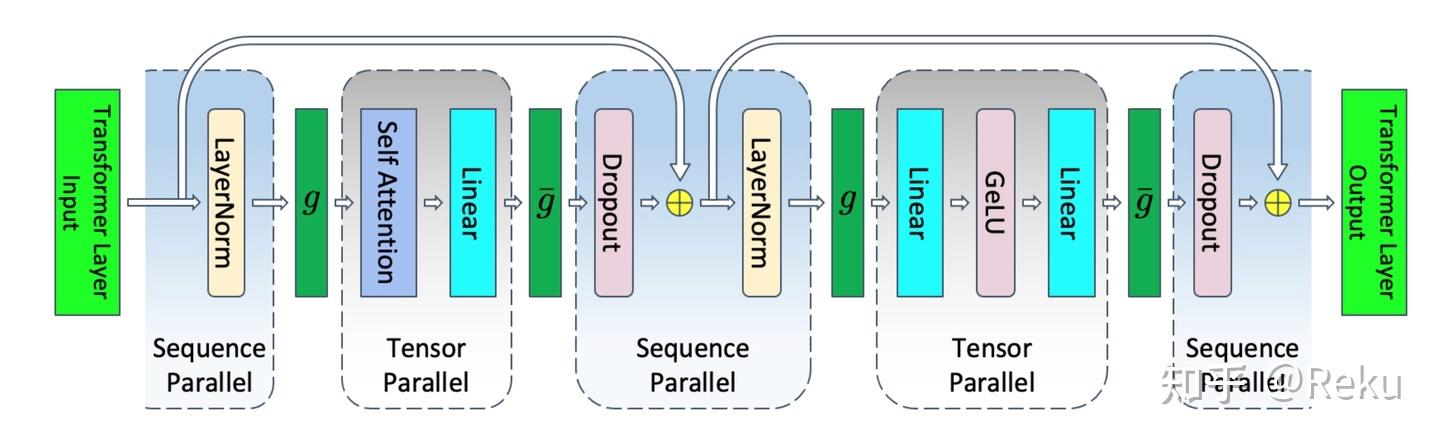
Megatron最开始的seq并行相对来说比较简单,transformer没切tp的地方都是element wise的。所以可以把tp的allreduce改成reducescatter,直接把N分到不同的卡上去做element wise的操作。序列并行转tensor并行的时候需要allgather,tensor并行转序列并行的时候需要reducescatter。这个方法的优点就是简单,缺点就是通信量比较大,而且序列并行的通信域被TP域的限制住,拓展不了特别大。
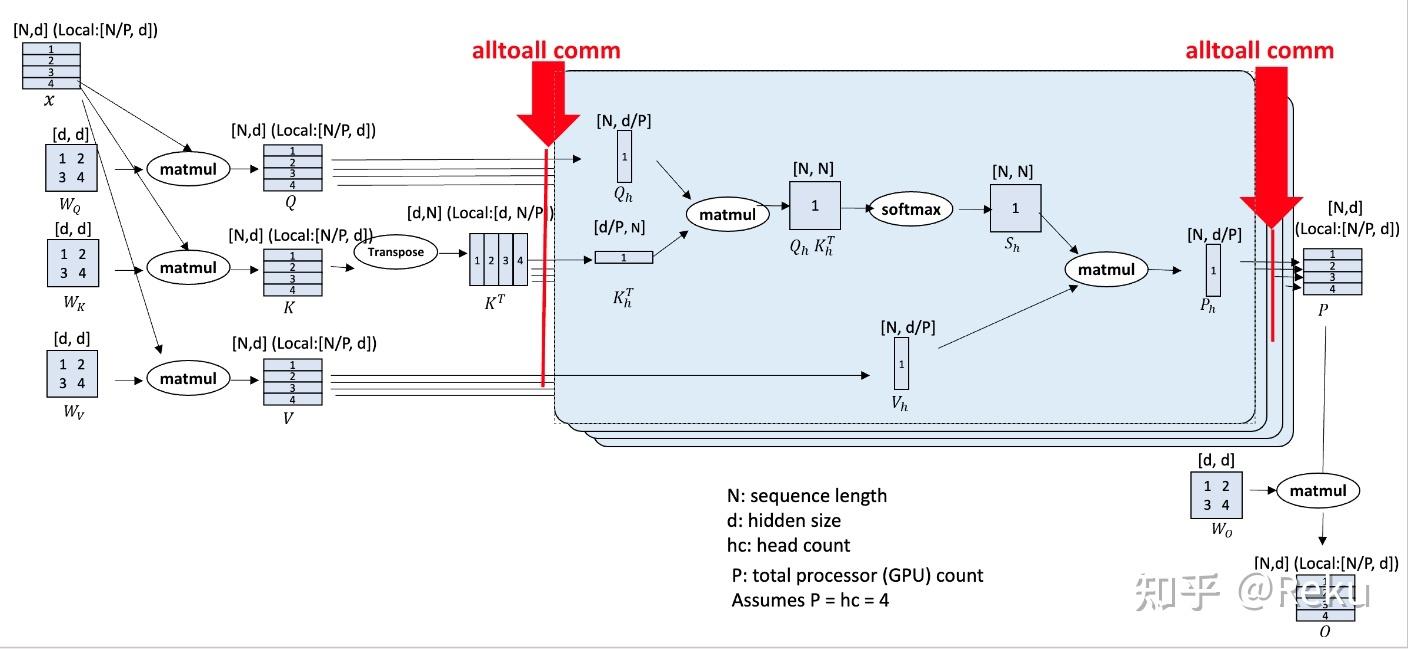
DeepSpeed采用的方式叫做deepspeed ulysses。核心点就是除了attention之外的部分(rmsnorm、matmul)切N都比较方便,只有attention不好切N,切head比较方便。那就是在进出attention的时候做一下切N和切head的转换,这里转换的方式使用了alltoall的通信源语,就是个分布式转置:
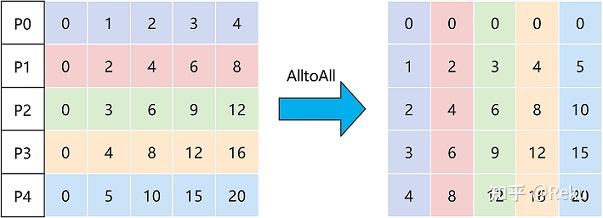
deepspeed ulysses的优点是通信量,成比例增加序列长度和device数量的时候,可以维持一个稳定的通信量。但和megatron的方式类似,切分数量被head num限制住,没法把序列切的特别小。
混合序列并行
实际上megatron sp和deepspeed ulysses都可以叠加ring-attention,把attention做进一步细分。megatron官网给了一个tp2cp2的例子,cp和tp共用四张卡,可以发现同一个序列的attention被切到两个部分了,这里的合并就是借助ring-attention的方式:
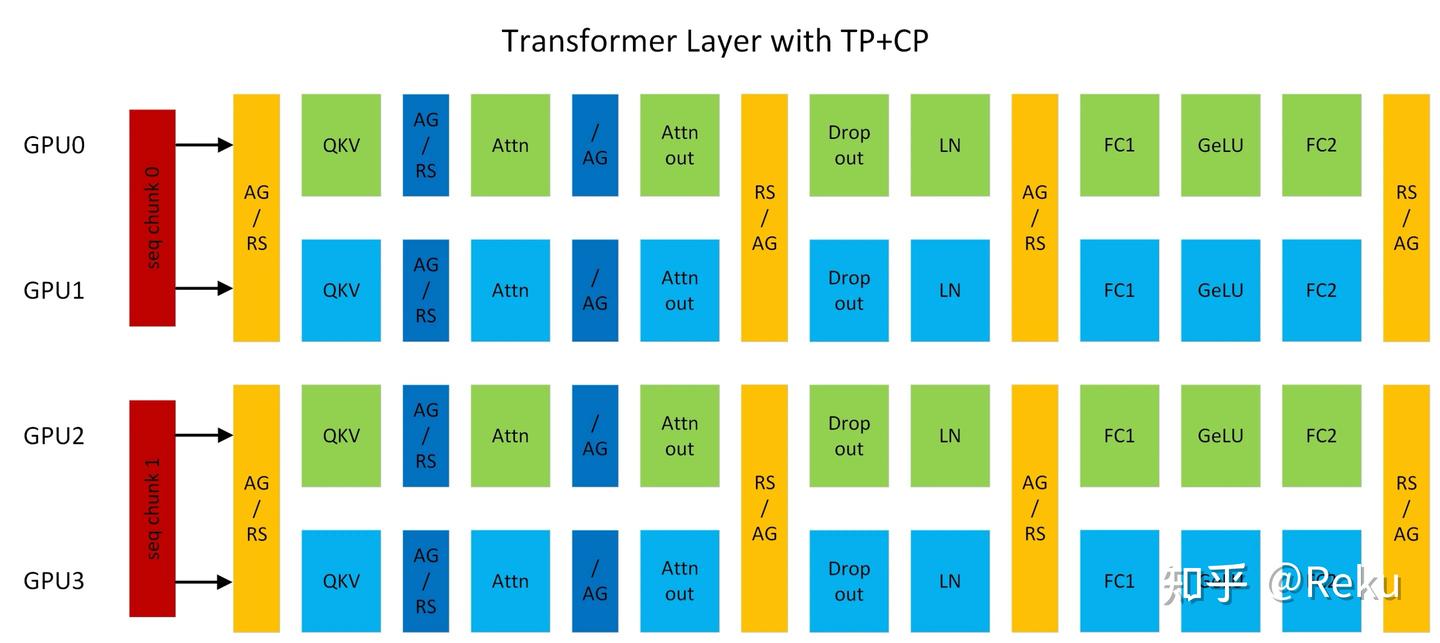
和deepspeed ulysses的结合思路也类似,在attention部分进一步切分。这样就可以解除head num对deepspeed ulysses的约束,可以把序列进一步细分。

后面遇到其他并行优化,比如seqpp之类的,就知道attention部分是怎么切分,需要处理些什么了。当然想实现最好的性能还需要非常多的细节。
参考
DefTruth:[Attention优化][2w字] 原理篇: 从Online-Softmax到FlashAttention V1/V2/V3
朱小霖:ring attention + flash attention:超长上下文之路
猛猿:图解大模型训练系列:序列并行2,DeepSpeed Ulysses
方佳瑞:大模型训练之序列并行双雄:DeepSpeed Ulysses & Ring-Attention
猛猿:图解大模型训练系列:序列并行4,Megatron Context Parallel
DeepSpeed/blogs/deepspeed-ulysses/chinese/README.md at master · deepspeedai/DeepSpeed
USP: A Unified Sequence Parallelism Approach for Long Context Generative AI
Reducing Activation Recomputation in Large Transformer Models
Ring Attention with Blockwise Transformers for Near-Infinite Context