OpenRLHF
SPMD(单程序多数据)
https://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/cli/train_ppo.py
用SPMD做LLM RL不需要太复杂的系统设计,因为当前深度学习最广泛使用的分布式范式就是SPMD,遵循大部分算法框架的设计方式就好了。OpenRLHF SPMD ppo的系统架构很简单:
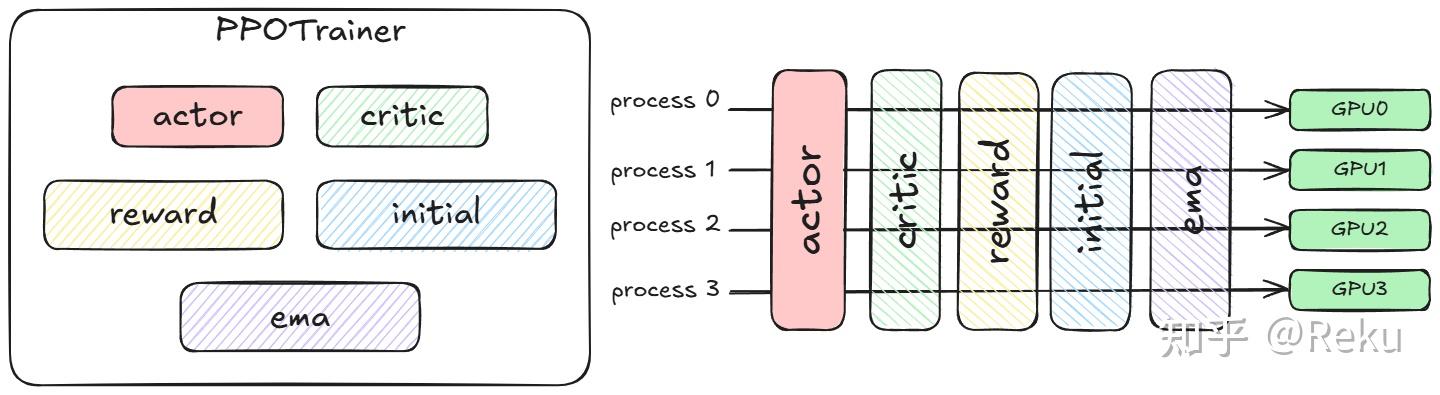
基于各种配置项初始化出对应的模型后,将这些模型传入PPOTrainer中。PPOTrainer负责整个PPO算法的控制逻辑。此时,不同的模型在同一组卡和同一组进程上按照不同的时间片运行SPMD。这些共享同一组计算资源并按时间交替使用的模型被称为colocate models。
MPMD(多程序多数据)
https://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/cli/train_ppo_ray.py
SPMD虽然实现简单,但它要求不同的模型只能串行执行,即使没有数据依赖的模型也难以实现并发。由于强化学习涉及的模型数量较多,如果某些模型不需要占用全部计算卡,就会导致部分计算资源的闲置。此外,SPMD需要将多个模型的参数同时加载到一张计算卡上,如果不结合offload等技术,很容易引发显存OOM问题。
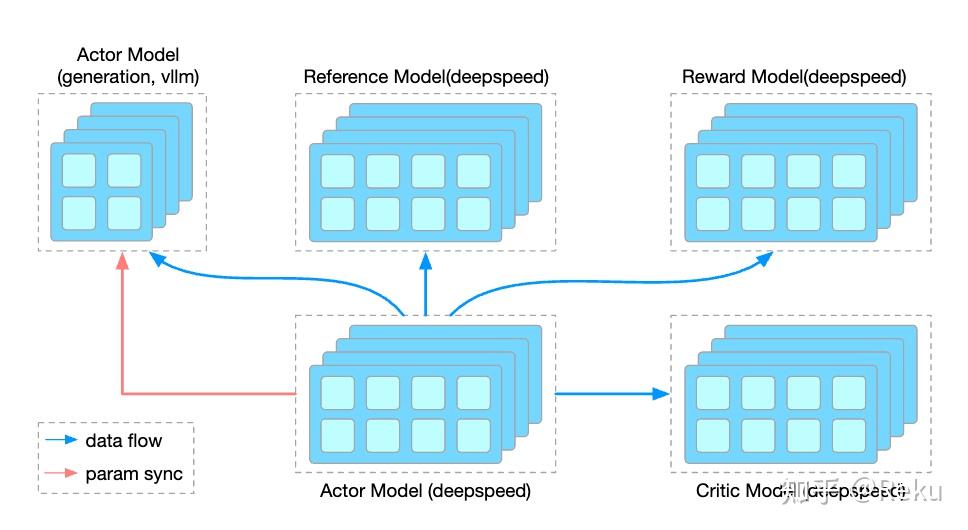
所以,OpenRLHF还支持使用ray进行拉起。使用ray的好处是可以通过配置placement group,让模型绑定到不同的卡上,并通过ray完成不同进程的数据交换。这里参考train_ppo_ray.py,画一下critic和actor-ref分离部署的场景示意图:
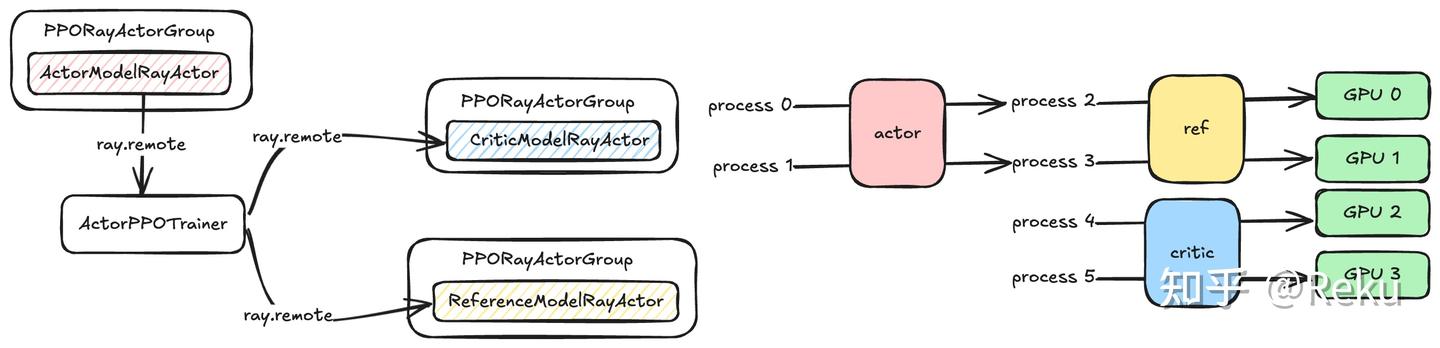
其实能很明显的看出来,OpenRLHF的ray流程基本上就是在SPMD流程上硬改过来的,并不像下面的verl一样,是基于ray的原生系统设计。有两点比较别扭:
- PPORayActorGroup都在主进程(或者叫driver process)实例化,但是算法的控制逻辑不在主进程上,而是在Actor对应的PPORayActorGroup里面(ActorPPOTrainer)。不同的PPORayActorGroup在逻辑上不是对等的,Actor所在PPORayActorGroup需要把RL算法中的所有组件串起来。当然了,这样实现Trainer的逻辑不需要大改,只需要从SPMD的PPOTrainer继承出来一个ActorPPOTrainer就行了,仅仅是架构概念上不太符合单一职责原则,真的要去理解流程还是比较清晰易懂的。
- colocate的模型不能放在同一个进程。参考上面的图,actor和ref共部署在相同的placement group上,但因为主体控制逻辑在ActorPPOTrainer里面,他也不知道ref是不是和他共部署,所以critic和ref都只能通过.remote的方式去调用。最后的效果就是,ref虽然和actor跑在一张卡上,但是二者不在同一个进程里面。这个设计会影响很多优化的开展,之前讲了深度学习最广泛使用的分布式范式就是SPMD,从深度学习框架到底层的device,都认为大部分场景(或者极致性能的场景)下device和process是一对一的,通信、显存资源都按照process级别去做共享。以显存为例,把用过的显存缓存下来是最基本的性能优化手段,但colocate的模型不在同一个进程上,就需要频繁的empty_cache来释放显存给卡上的另一个进程。老调重弹,对于国产芯片和框架,这种设计对架构更是巨大冲撞。
当然,好处就是系统设计的很清晰,相比verl的层层封装,OpenRLHF想动手改点东西是很简单的,算法工程师们也可以轻松理解。
OpenRLHF的简洁设计有一个很重要的前提,就是模型基本都是dp分片的(vllm里面有tp分片),训练基于FSDP或者deepspeed,分布式优化靠的都是zero系列。这种设计的好处是数据流通起来很方便,就算RL框架里面最复杂的actor推理训练权重同步,在OpenRLHF里面也只需要一个broadcast(因为vllm只会再多个TP分片)。因为都是dp分片,不同rank是完全对等的,不同模型的调度可以直接轮询。但正是这种选择,导致OpenRLHF在大集群上训练超大规模的网络很难用,只用dp是没法跑满血的deepseek v3的。
verl
verl的论文写了single controller/multi-controller、zero redundancy model resharding之类的贡献点。但我这里直接恶意揣测一下,verl最核心的动机以及设计上最漂亮的点是colocate模型的共进程,这一点对系统优化非常关键,但是不好发论文吹牛,所以包装了几个点出来发论文。
https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py
https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py
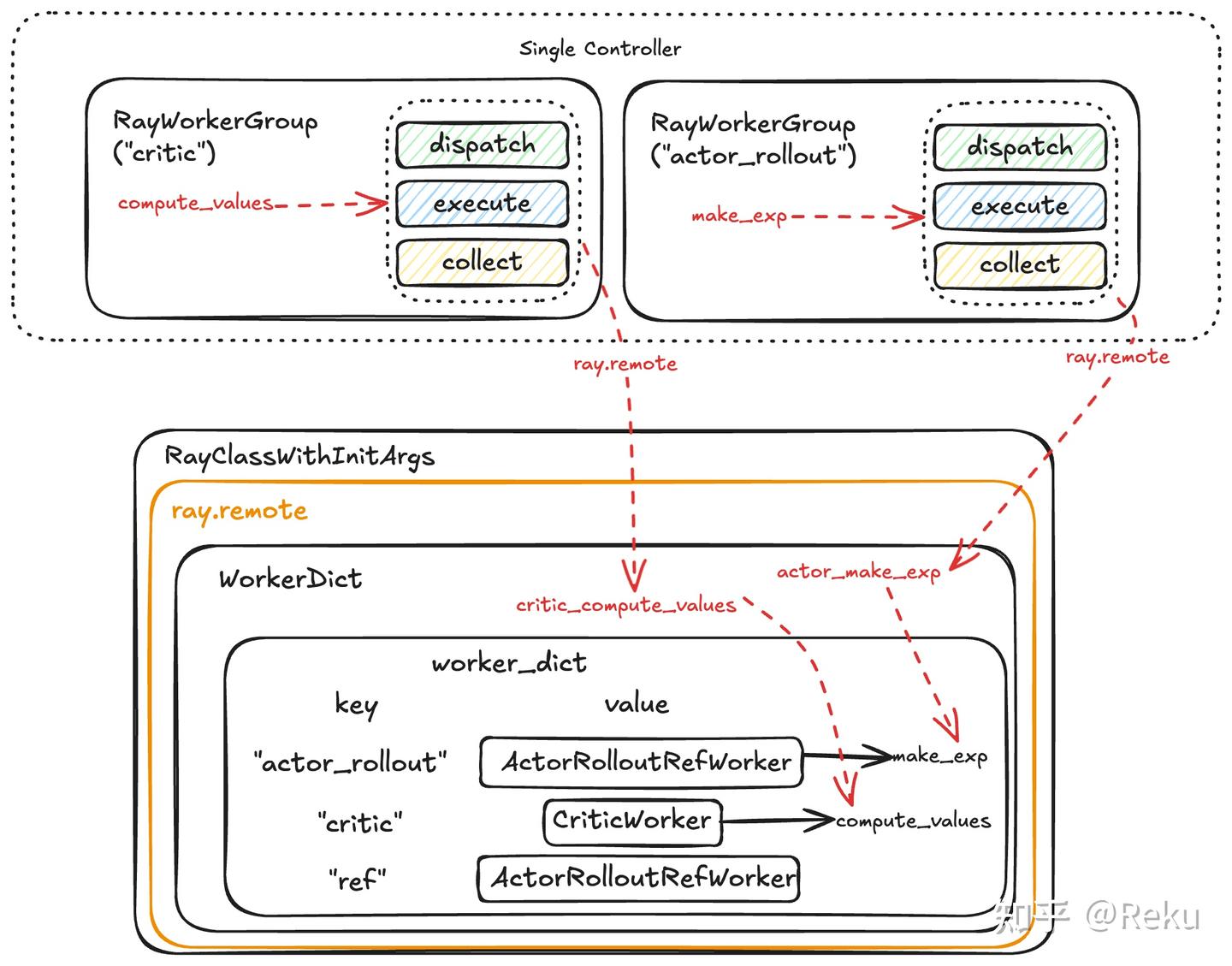
上面OpenRLHF的ray流程最大缺点就是colocate模型没法共进程。想一下,要实现共进程这个特性,得让colocate的不同模型共享同一个ray remote实例。为了达成这个目的,并且让上层的编程接口尽量干净,verl做了巨复杂的封装,我上面画了个图,展示了层层封装之后最终的调用形态。
用户需要编写的是ActorRolloutRefWorker或CriticWorker等worker,并将这些worker传入RayPPOTrainer中。verl会自动将colocate的模型集中到一个WorkerDict中,并通过setattr为每个worker设置所需的方法,从而实现worker层面的任务分发。最终,系统会为每个worker生成一个RayWorkerGroup,这些RayWorkerGroup的对外接口与其对应的worker完全一致,但经过了多次转发。colocate的RayWorkerGroup的成员方法会转发到同一个WorkerDict中,以此实现共进程的执行机制。
此外,verl支持FSDP/Megatron等多种后端,也支持3D并行策略的配置,这样数据流动的方式就会很复杂。为了实现这个功能,verl搞了一套协议,自动在函数的前后插上对应并行方式的dispatch/collect方法。反正都把函数调用搞成这么复杂的闭包了,ray相关的操作(ray.gets/.remote)也可以隐藏在闭包里面(OpenRLHF要直接写在脚本上),主体逻辑就看起来很简洁。
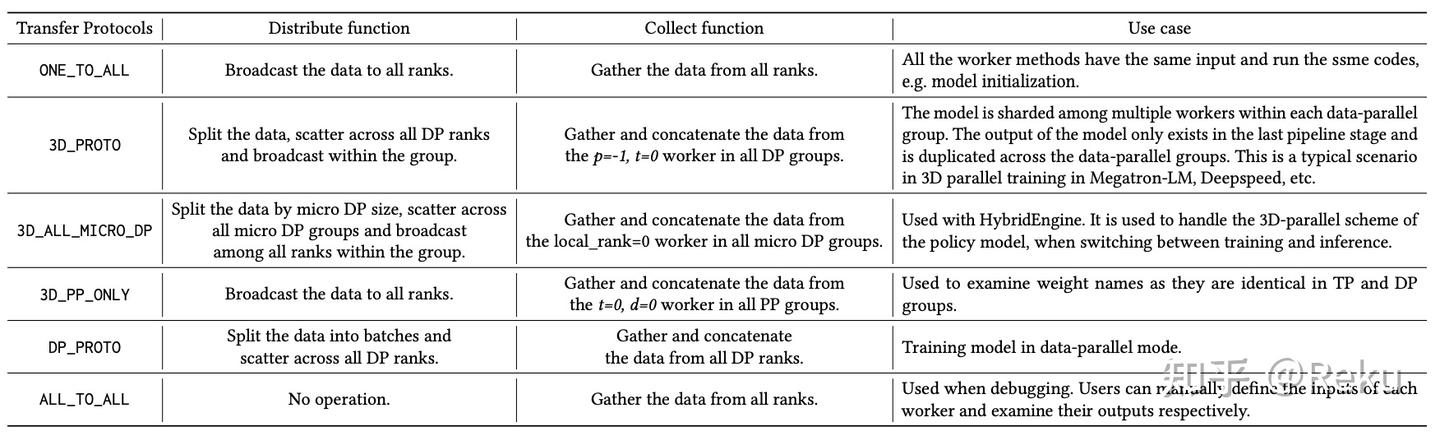

这个封装合不合适,见仁见智,对verl可能大部分人会有个螺旋上升的认识过程。首先看到fit函数这么简洁,肯定觉得很舒服;但后来发现每个函数怎么都点不进去,各种调用怎么一层套一层,就觉得这又是大公司开源狗屎给大家;最后明白了verl的设计理念,感叹人类的智慧。当然,如果不用大集群,7B/30B这种规模做做RL,还想自己改改东西,无脑推荐OpenRLHF。
One more thing:ray真的很重要吗?
回归前提,上一篇文章我猜RL算法的演进会越来越简洁,GRPO干掉了reward和critic。按照历史经验来看,RL需要的算力会越来越大,各种算法设计需要在大算力下充分验证。这一定会让RL走向力大砖飞的方向,各种小技巧会越来越少。在RL过程中,actor的推理和训练会越来越重,二者的系统差异也会越来越大,这两模块会吃掉所有的算力。为了达成更好的MFU,如果还是这种训练模式,actor训推共部署是必然的选择。在这个前提下,ray很可能是伪需求,最后还是回归到SPMD的怀抱。
参考
https://github.com/OpenRLHF/OpenRLHF
https://github.com/volcengine/verl
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
低级炼丹师:强化学习从零到RLHF(八)一图拆解RLHF中的PPO
不关岳岳的事:[AI Infra] VeRL 框架入门&代码带读