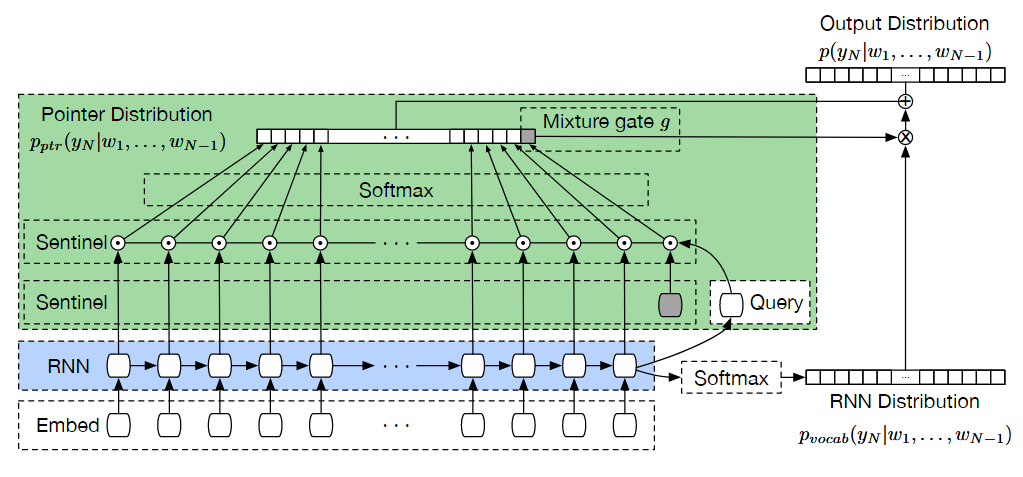
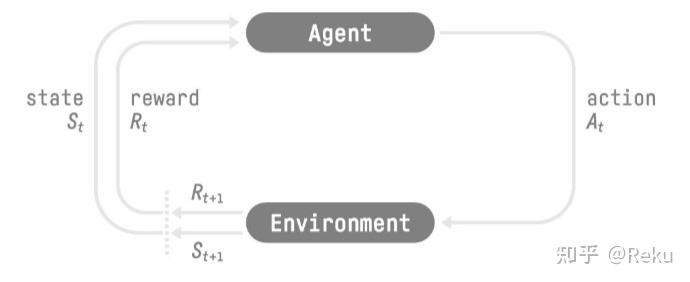
// Step 1: stream_wait synchronizes comm_stream with compute_stream // comm_stream will wait for everything *currently* enqueued on compute_stream stream_wait(comm_stream, compute_stream);
// Step 2: torch::empty() allocates tensors AFTER the sync point // When fill_uninitialized_memory=True, this launches a NaN-fill kernel // on compute_stream — which comm_stream does NOT wait for auto recv_x = torch::empty({num_recv_tokens, hidden}, x.options());
// Step 3: communication kernel runs on comm_stream, writing to recv_x intranode::combine(..., recv_x.data_ptr(), ..., comm_stream, ...);
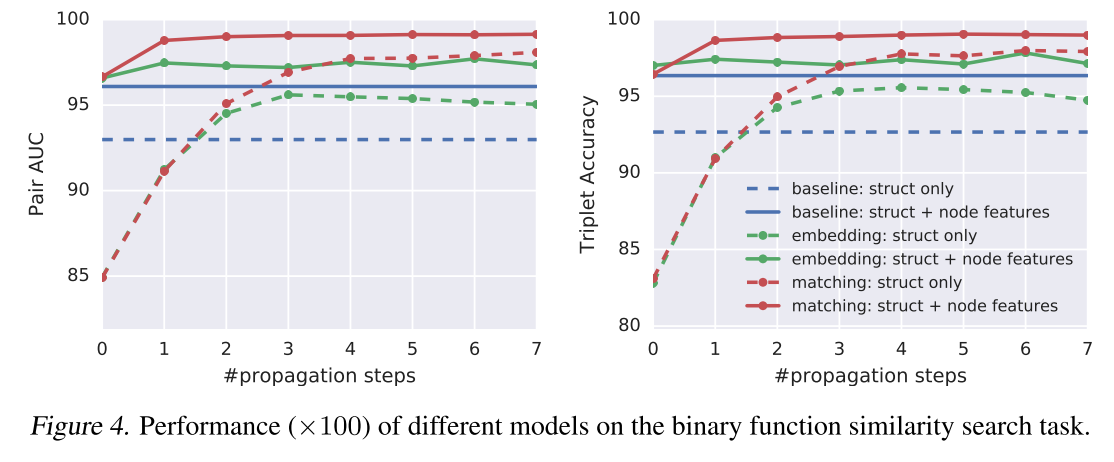
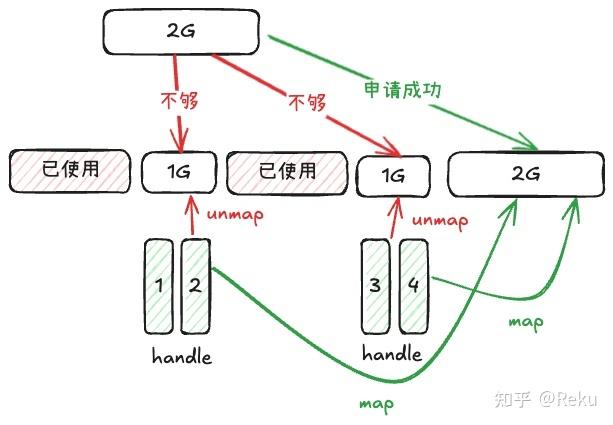
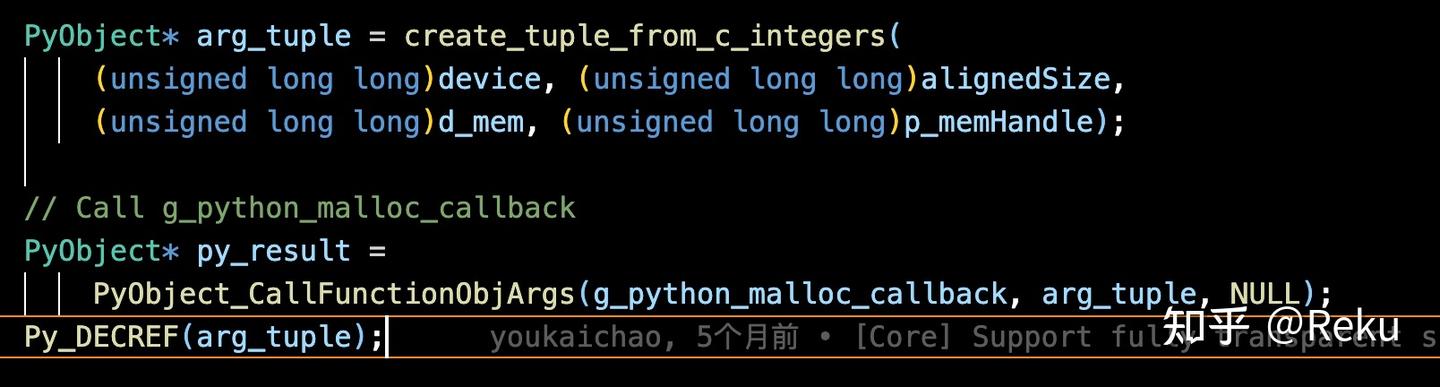
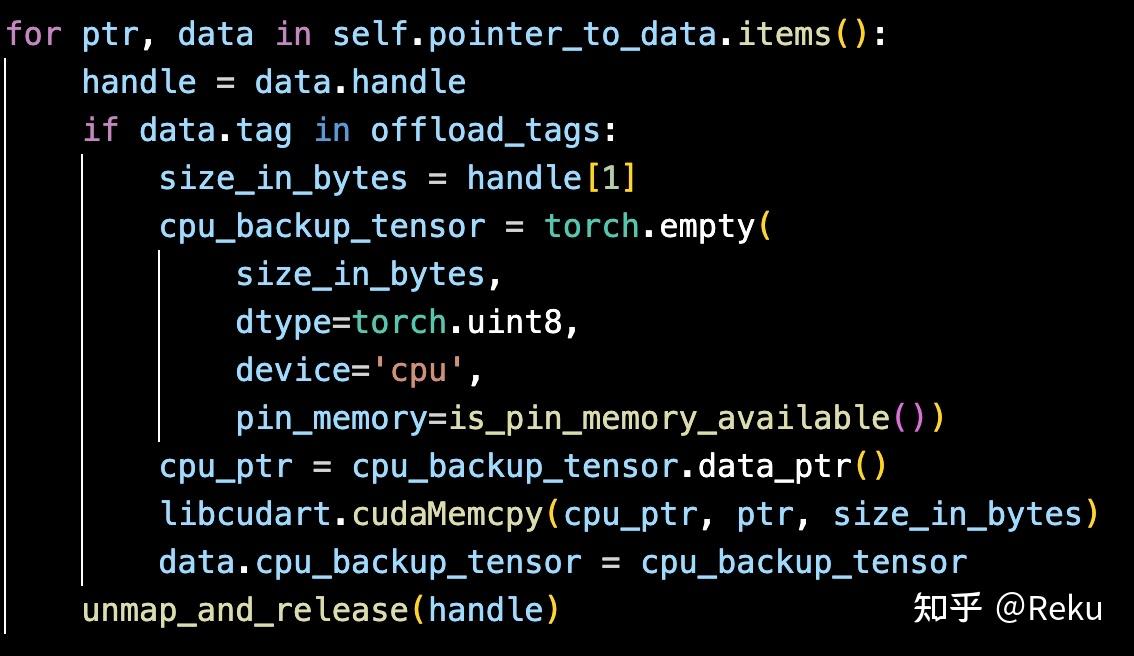
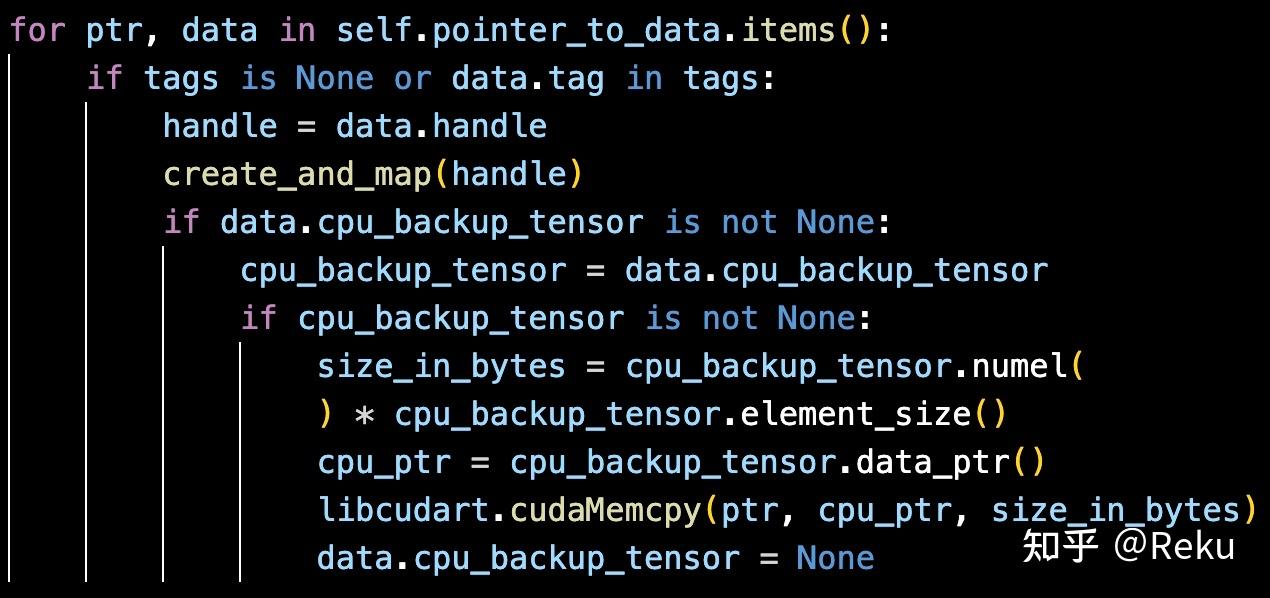
DeepEP 分配一块 empty 当输出,本来只有通信流在写数据,现在主流也会往里面写 nan,导致两个写操作并发了,制造了时序问题。这个问题的复现频率与 EP 执行速度、算子下发速度都有关系,所以看起来很复杂。
claude debug 成功之后,我是非常震撼的,因为这不是一个很简单的 bug,涉及到很多功能的交叉。各位 ai infra 程序员可以扪心自问一下,直接面对这个问题,大家要花几个工作日能定位出来,定位过程中心态会不会出现问题。但现在,我只是在娱乐过程中随便 prompt 了几下,claude 就全搞定了。
当然整个 vibe debug 过程没有这么顺利,如果公司没有活动,是正常的工作日,我可能对 claude 也没有这么多的耐心。这说明我们还是需要 agent 工程、需要 skills。但模型的智能已经够了,我觉得我不算很菜的程序员,但 opus 4.6 比我要强。
// Wait for inputs to arrive and store data to destination device wait(arrived, 0); tma::store_async(G.output[dst_dev_idx], tile, {batch_idx, depth_idx, row_block_idx, col_block_idx}); }
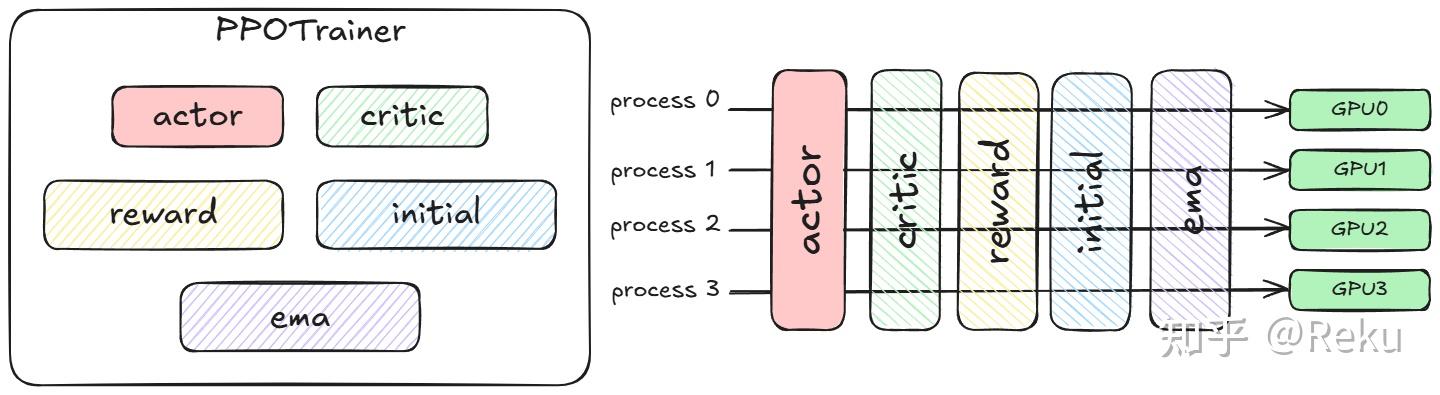
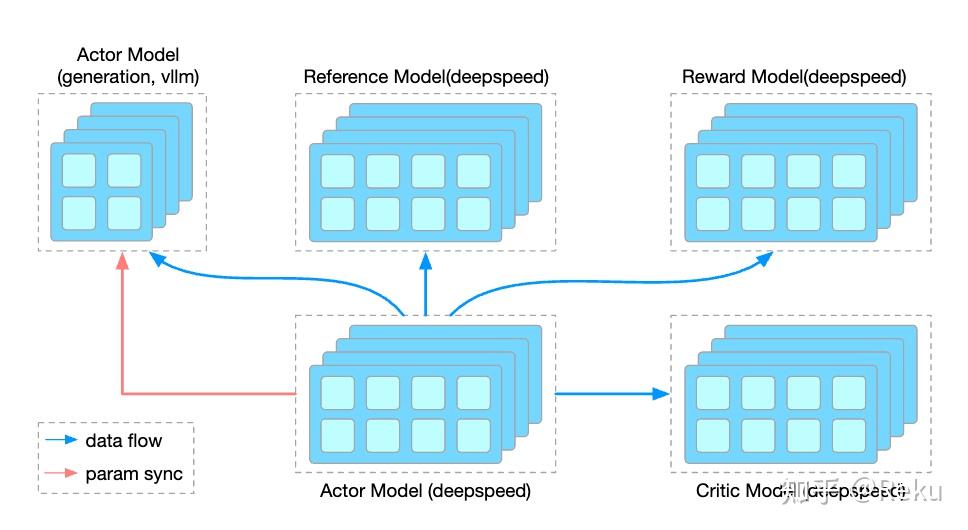
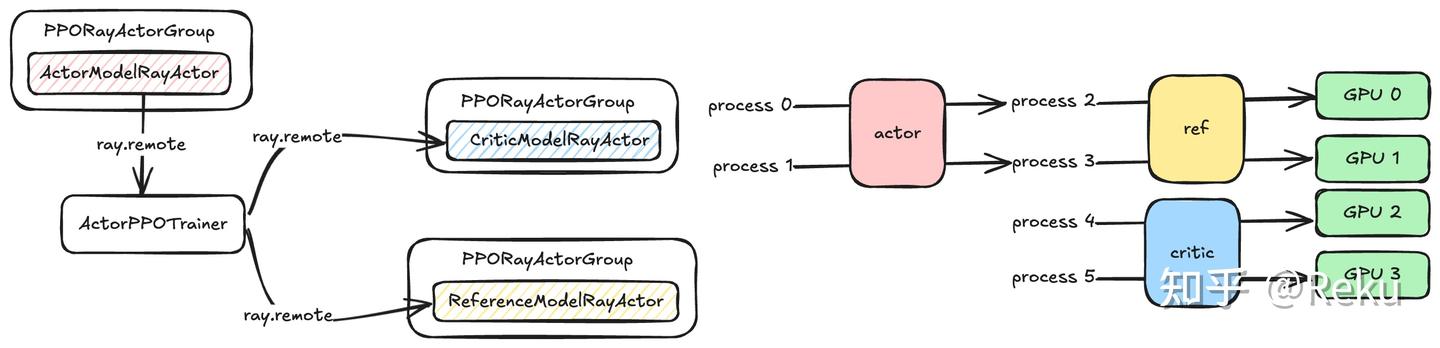
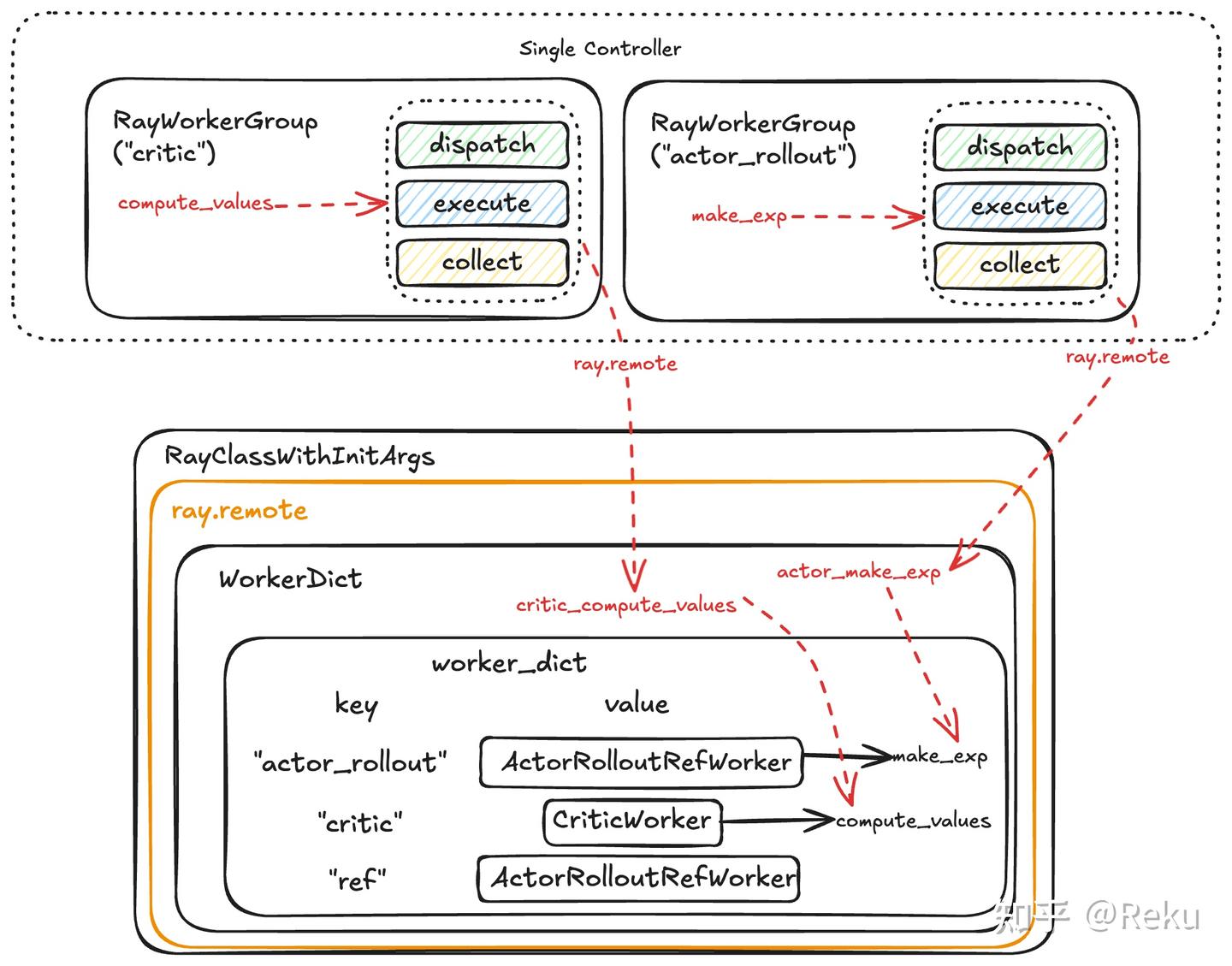
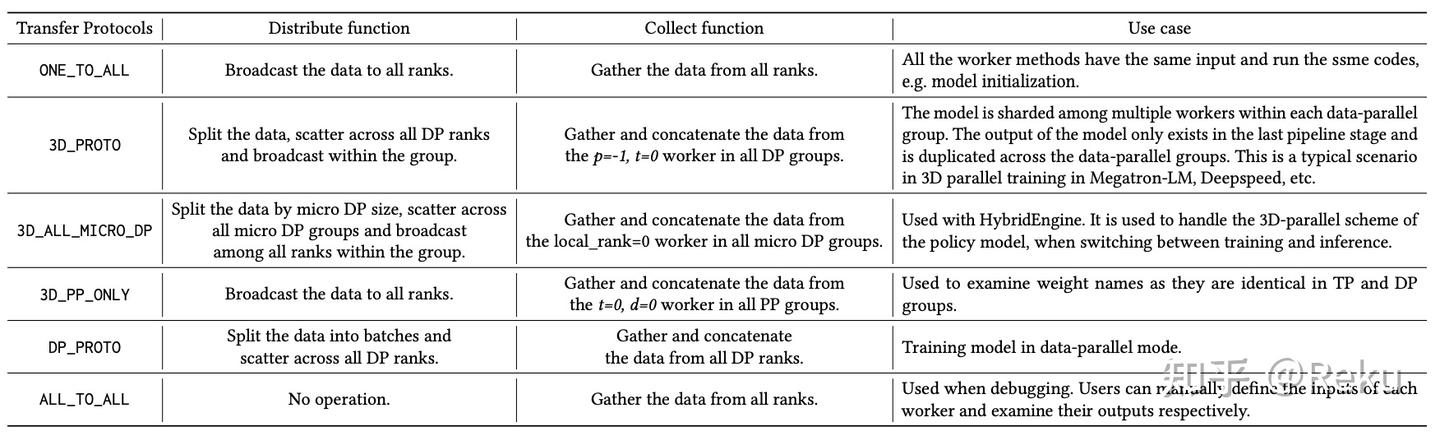
verl的论文写了single controller/multi-controller、zero redundancy model resharding之类的贡献点。但我这里直接恶意揣测一下,verl最核心的动机以及设计上最漂亮的点是colocate模型的共进程,这一点对系统优化非常关键,但是不好发论文吹牛,所以包装了几个点出来发论文。
The child process creates a pipe to connect the left end of the pipeline with the right end. Then it calls fork and runcmd for the left end of the pipeline and fork and runcmd for the right end, and waits for both to finish.
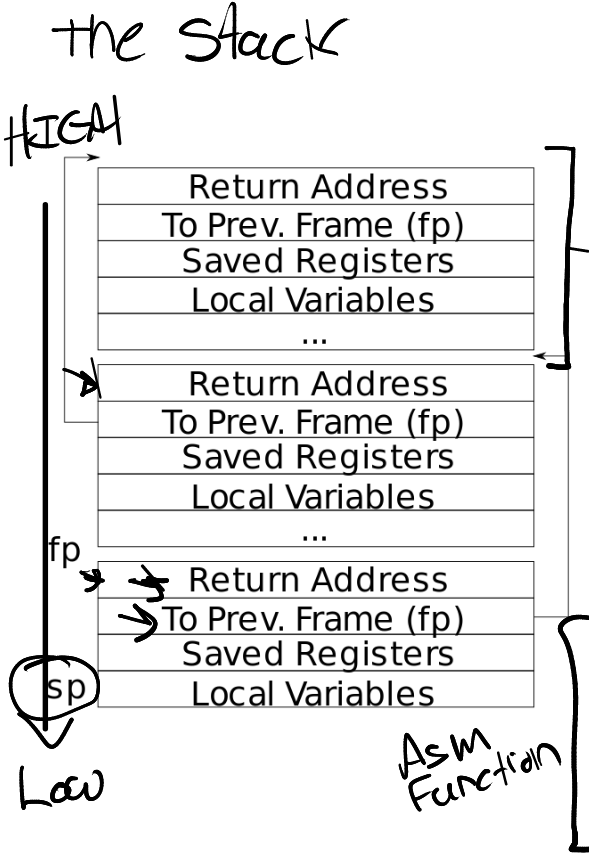
_entry: # set up a stack for C. # stack0 is declared in start.c, # with a 4096-byte stack per CPU. # sp = stack0 + (hartid * 4096) la sp, stack0 li a0, 1024*4 csrr a1, mhartid addi a1, a1, 1 mul a0, a0, a1 add sp, sp, a0 # jump to start() in start.c call start
void start() { // set M Previous Privilege mode to Supervisor, for mret. unsignedlong x = r_mstatus(); x &= ~MSTATUS_MPP_MASK; x |= MSTATUS_MPP_S; w_mstatus(x);
// set M Exception Program Counter to main, for mret. // requires gcc -mcmodel=medany w_mepc((uint64)main);
// disable paging for now. w_satp(0);
// delegate all interrupts and exceptions to supervisor mode. w_medeleg(0xffff); w_mideleg(0xffff); w_sie(r_sie() | SIE_SEIE | SIE_STIE | SIE_SSIE);
// ask for clock interrupts. timerinit();
// keep each CPU's hartid in its tp register, for cpuid(). int id = r_mhartid(); w_tp(id);
// switch to supervisor mode and jump to main(). asmvolatile("mret"); }
// give up the CPU if this is a timer interrupt. if(which_dev == 2) { p->timer ++; if (p->timer == p->ticks) { p->timer = 0; p->trapframe->epc = (uint64)p->handler; } yield(); }
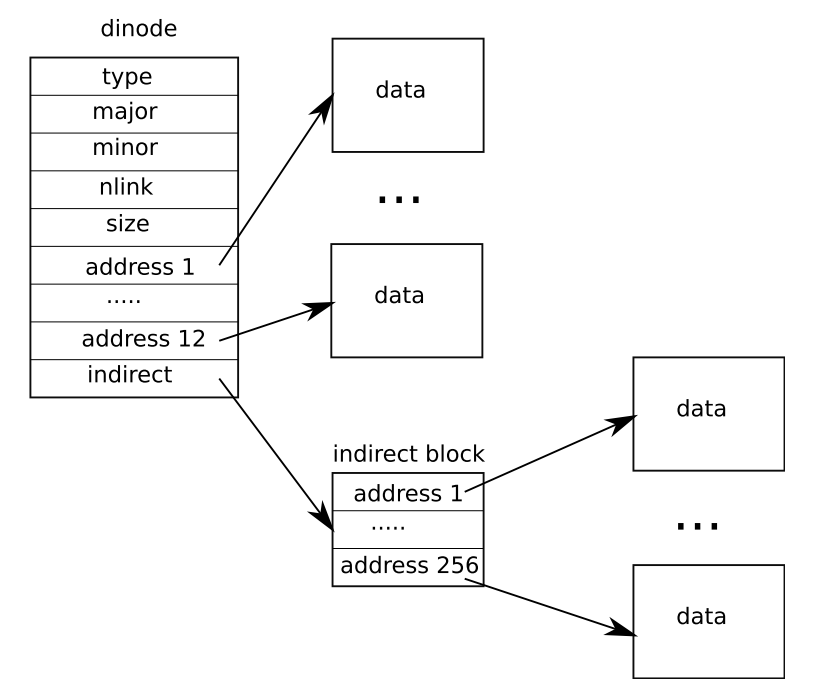
这个任务的难点在于要清晰的了解他想让你实现的 Symbolic links 行为到底是什么样子的。当 open 不带有 O_NOFOLLOW 标记时,需要一直向下找到 hard link 的位置。整个 symbolic link 的内容都要放在对应的 inode 上面,实际上只需要自己去将文件路径和路径长度保存在 inode 里面就可以了。
void mmaplazyalloc(int va) { structproc *p = myproc(); int found = 0, i = 0; for (i = 0; i < 16; i++) { if (p->mmaps[i].used) { uint64 start = p->mmaps[i].addr; uint64 end = p->mmaps[i].addr + p->mmaps[i].length; if (va >= start && va < end) { found = 1; break; } } } if (found == 0) return; structfile *f = p->mmaps[i].f; int offset = p->mmaps[i].offset; uint64 off = offset + va - p->mmaps[i].addr;
begin_op(); ilock(f->ip); if (readi(f->ip, 1, va, off, PGSIZE) < 0) { panic("lazyalloc read."); } iunlock(f->ip); end_op(); }
最后一个实验了,非常简单,就是让我们实现 e1000_transmit 和 e1000_recv 这两个函数。看起来仿佛非常复杂,实际上按照 hint 模拟就好了。
但是有个地方需要注意,在 hint 中, e1000_recv 实现方式如下:
Some hints for implementing e1000_recv: First ask the E1000 for the ring index at which the next waiting received packet (if any) is located, by fetching the E1000_RDT control register and adding one modulo RX_RING_SIZE. Then check if a new packet is available by checking for the E1000_RXD_STAT_DD bit in the status portion of the descriptor. If not, stop. Otherwise, update the mbuf's m->len to the length reported in the descriptor. Deliver the mbuf to the network stack using net_rx(). Then allocate a new mbuf using mbufalloc() to replace the one just given to net_rx(). Program its data pointer (m->head) into the descriptor. Clear the descriptor's status bits to zero. Finally, update the E1000_RDT register to be the index of the last ring descriptor processed. e1000_init() initializes the RX ring with mbufs, and you'll want to look at how it does that and perhaps borrow code. At some point the total number of packets that have ever arrived will exceed the ring size (16); make sure your code can handle that.
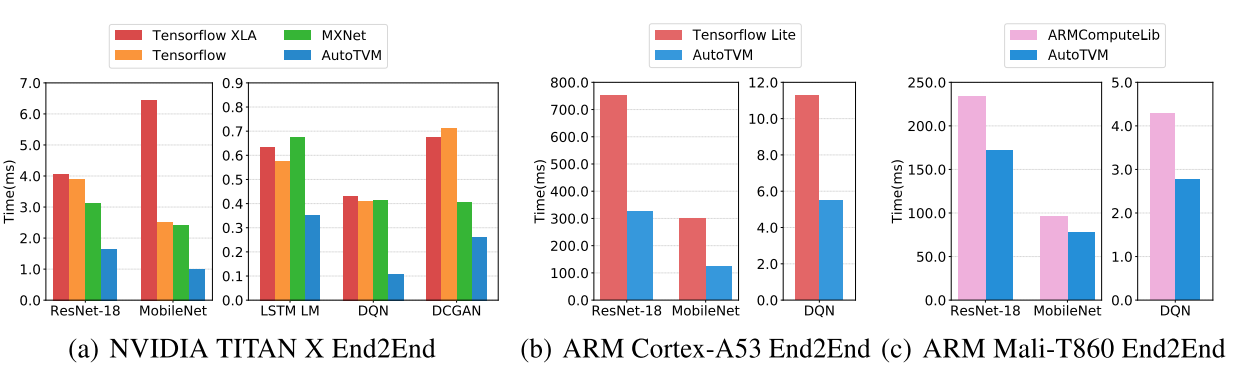
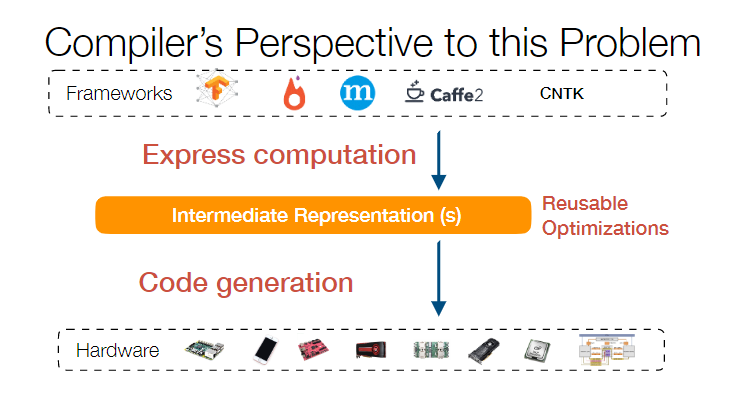
Apache TVM (incubating) is a compiler stack for deep learning systems. It is designed to close the gap between the productivity-focused deep learning frameworks, and the performance- and efficiency-focused hardware backends. TVM works with deep learning frameworks to provide end to end compilation to different backends.
@autotvm.template defmatmul(N, L, M, dtype): A = tvm.placeholder((N, L), name='A', dtype=dtype) B = tvm.placeholder((L, M), name='B', dtype=dtype)
k = tvm.reduce_axis((0, L), name='k') C = tvm.compute((N, M), lambda i, j: tvm.sum(A[i, k] * B[k, j], axis=k), name='C') s = tvm.create_schedule(C.op)
# schedule y, x = s[C].op.axis k = s[C].op.reduce_axis[0]
##### define space begin ##### cfg = autotvm.get_config() cfg.define_split("tile_y", y, num_outputs=2) cfg.define_split("tile_x", x, num_outputs=2) ##### define space end #####
# schedule according to config yo, yi = cfg["tile_y"].apply(s, C, y) xo, xi = cfg["tile_x"].apply(s, C, x)
s[C].reorder(yo, xo, k, yi, xi)
return s, [A, B, C]
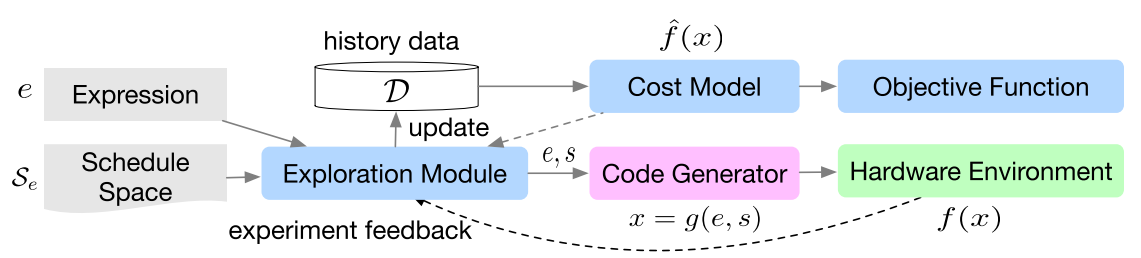
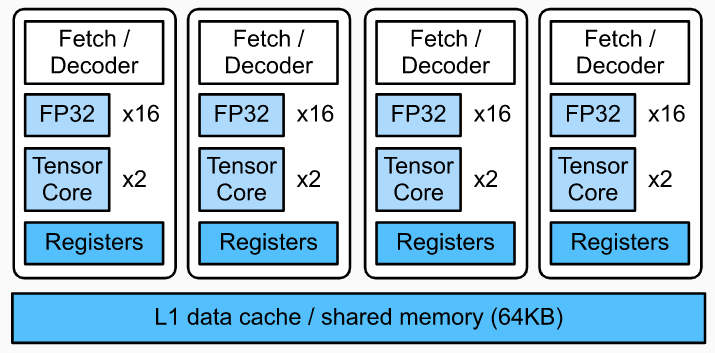
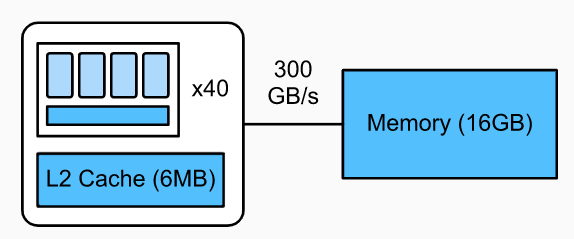
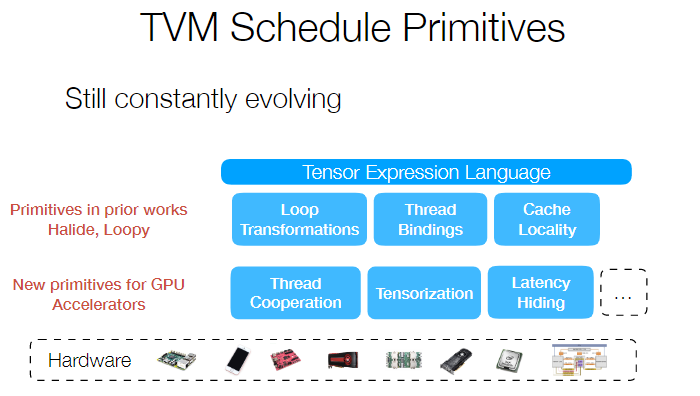
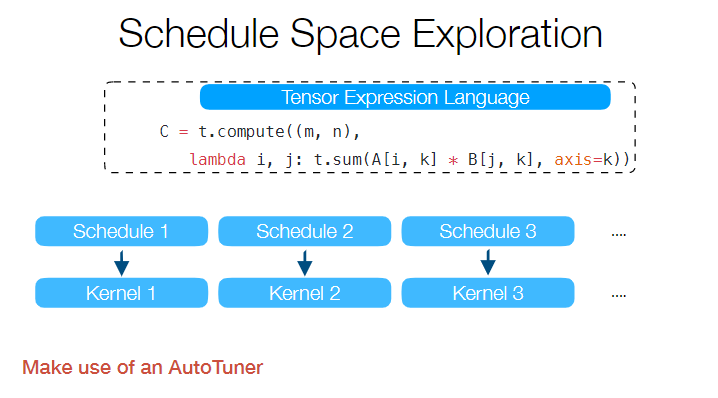
这其实也是系统设计的艺术,首先 TVM 把运算与 schedule 进行解耦,然后一部分 schedule 由用户进行实现,一部分需要精细调整的内容由一个 ML 算法进行搜索,从而达到一个易用性和性能的 trade-off。相对应的是 Facebook 做的 Tensor Comprehension,要解决的问题跟 TVM 是类似的,但是选择的是利用 polyhedra model 进行一个类似端到端的优化过程,但是优化的空间其实比 TVM 这种 schedule space 模型要差一些,所以效果也会打些折扣。一些相关的讨论可以在如何看待Tensor Comprehensions?与TVM有何异同?上面看到。 对于 GPU 来说,由于架构跟 CPU 存在区别,所以优化的方式也不太一样:
# tile and bind spatial axes n, f, y, x = s[output].op.axis bf, vf, tf, fi = cfg["tile_f"].apply(s, output, f) by, vy, ty, yi = cfg["tile_y"].apply(s, output, y) bx, vx, tx, xi = cfg["tile_x"].apply(s, output, x) kernel_scope = n # this is the scope to attach global config inside this kernel
]]><p>周末要在实验室搞个类似讲座之类的东西,先在这里写一下讲座内容,理清思路。也是对最近一个月的学习内容做一个总结。</p>CSE 599W: SYSTEMS FOR ML 课程笔记 7-12https://wyc-ruiker.github.io/2019/11/21/cse-599w-systems-for-ml-7-12/2019-11-21T07:04:48.000Z2021-12-16T11:33:10.000Z各种课程资料请参考上一篇文章
当然了,最后 IR 如果想要运行,那你还是要把 IR 变成机器码才可以。对于不同的硬件平台、数据格式、精度、线程结构都要写一堆不同的代码生成规则和优化规则。 这个问题是 TVM 的技术背景了。前面说了,如果还解决不了问题,那就再加个中间层。TVM 加的中间层就是所谓的 Tensor Expression Language 表示方法。这个 idea 来自于 Halide,核心在于把代码的计算和调度分开。
举个具体的例子,最简单的一个向量相加,用 TVM 实现起来长这样:
1 2
C = tvm.compute((n,), lambda i: A[i] + B[i]) s = tvm.create_schedule(C.op)
得到的 C 代码是:
1 2 3 4
for (int i = 0; i < n; ++i) { C[i] = A[i] + B[i]; }
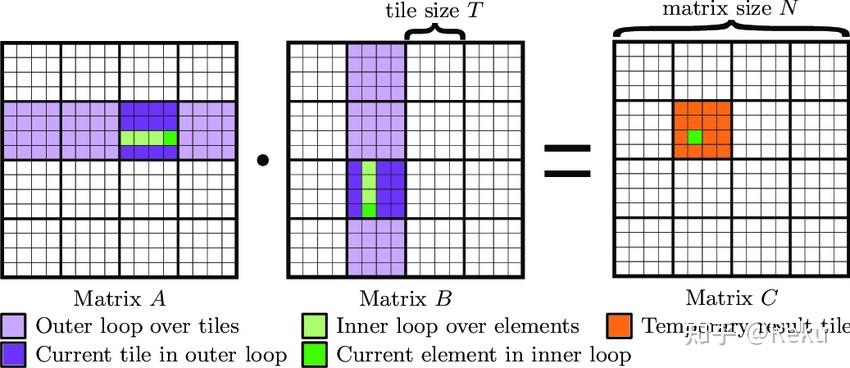
加上一些额外的循环控制(就是上篇文章中讲的 cache 优化)
1 2 3
C = tvm.compute((n,), lambda i: A[i] + B[i]) s = tvm.create_schedule(C.op) xo, xi = s[C].split(s[C].axis[0], factor=32)
生成的代码就变成了:
1 2 3 4 5 6 7 8 9 10 11
for (int xo = 0; xo < ceil(n / 32); ++xo) { for (int xi = 0; xi < 32; ++xi) { int i = xo * 32 + xi; if (i < n) { C[i] = A[i] + B[i]; } } }
甚至可以绑定特定的变量:
1 2 3 4 5 6
C = tvm.compute((n,), lambda i: A[i] + B[i]) s = tvm.create_schedule(C.op) xo, xi = s[C].split(s[C].axis[0], factor=32) s[C].recorder(xi, xo) s[C].bind(xo, tvm.thread_axis(“blockIdx.x”) s[C].bind(xi, tvm.thread_axis(“threadIdx.x”)
这样就出来一个 CUDA kernel 代码:
1 2 3 4 5
int i = threadIdx.x * 32 + blockIdx.x; if (i < n) { C[i] = A[i] + B[i]; }
]]><p>各种课程资料请参考<a href="https://reku1997.gitee.io/2019/11/08/cse-599w-systems-for-ml-1-6/">上一篇文章</a></p>CSE 599W: Systems for ML 课程笔记 1-6https://wyc-ruiker.github.io/2019/11/08/cse-599w-systems-for-ml-1-6/2019-11-08T07:31:51.000Z2021-12-16T11:33:12.000Z课程网站 在头条 AML 实习的时候就觉得这个 AI system 方向非常有趣,但是苦于实验室不是搞这一套的,自己拖延症也非常严重,所以一直在入门的边缘徘徊。但是在今天——研一秋学期考试周的前一周,我决定开始学习 AI system 方向最著名的必学课程,Tianqi Chen 在 UW 开设的 CSE599W。 这个课程其实资料并不是很完善,只有 github 上面的几个 repo 和课程网站上面的 slide,缺乏讲课的视频资源。而且在开始学习之前就听说很多地方 slide 写的非常简陋,只能通过 tvm 和 tinyflow 代码慢慢学习。我在学习之前也找了一些 blog 资源,开个坑,希望可以努力坚持下来! 本人的作业也开源到 github 上面了,希望大家多多指导。
介绍了一波深度学习的基本概念,常见的各种 CNN、RNN、激活函数、BatchNormal、梯度消失与梯度爆炸都用一节课介绍了一通。因为我之前学过 Ng 在 coursera 上面的 Deep learing 专项,所以对这些都很了解了,而且这些内容的资源满大街都是,就不在这里继续介绍了。 第二讲是一个实验课,用 mxnet 搭建一个基础的网络,虽然我之前系统看过沐神的《动手深度学习》,但是我看的是 github 上面的 pytorch 魔改版,mxnet 只在上半年的华为软挑的时候用过一下,不是特别了解。但是这个 gluon api 似乎跟 pytorch 大同小异,这里也不多废话了,有兴趣自己看看原版《动手深度学习》就好了。
Lecture 3: Overview of Deep Learning System
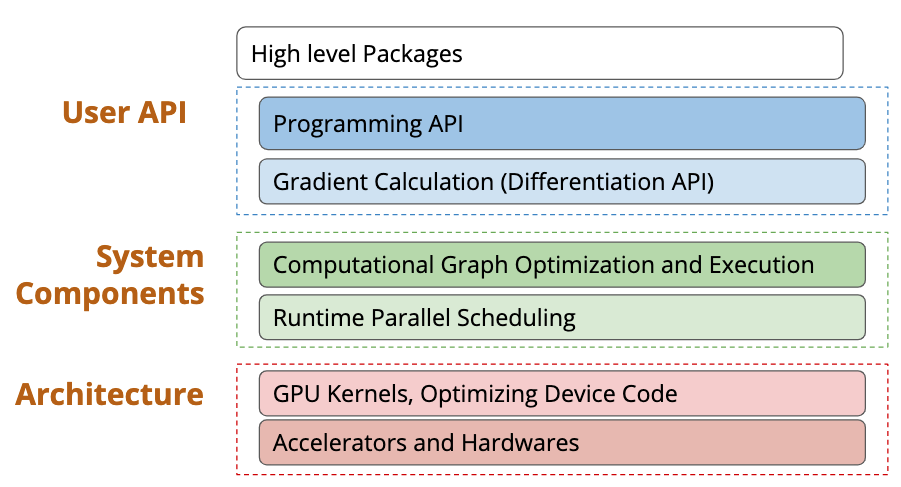
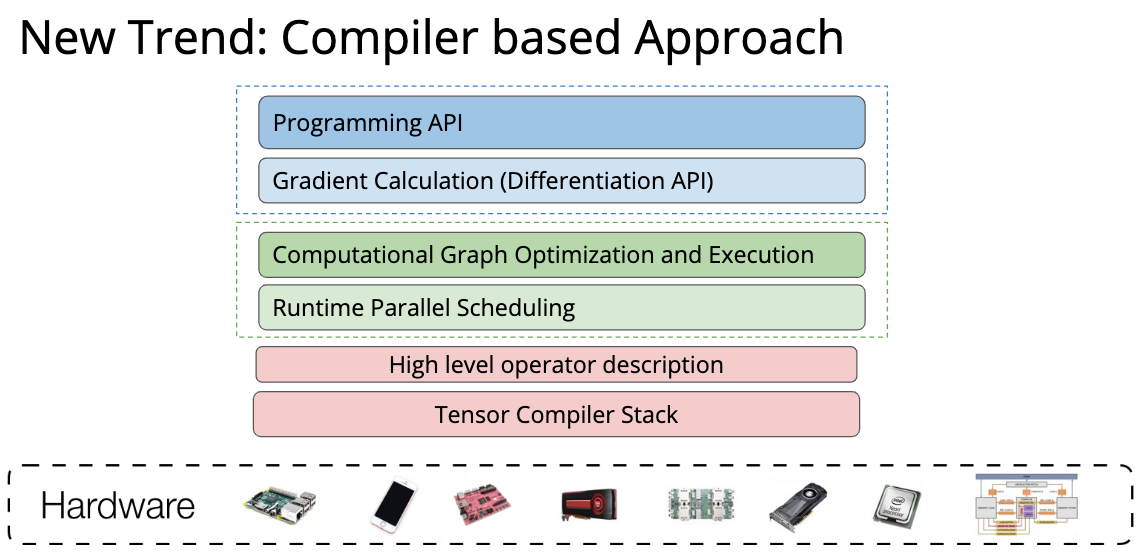
学习过什么是 Deep Learning 了,那么啥是 Deep Learning System 呢? 在我的理解其实就是从调包到真正计算出结果的全过程,就是 Deep Learning System,也就是通常所说的算法的真正落地。 在这个课程中,Deep Learning System 从高层到底层分成了三个部分:
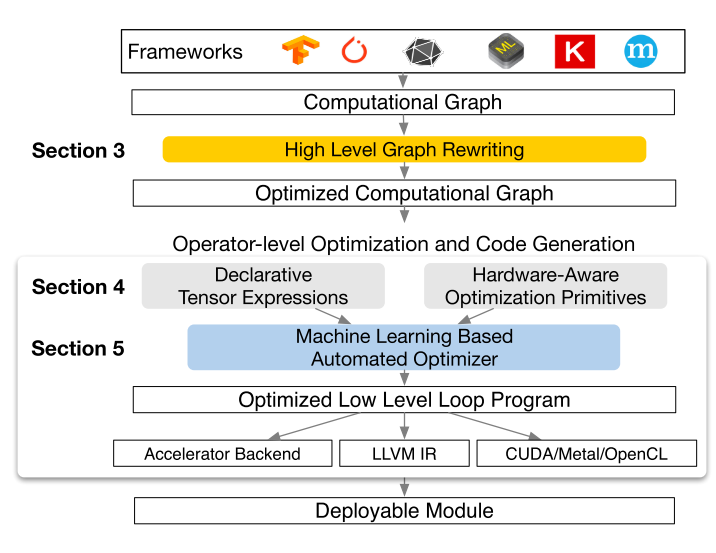
第一部分就是调包的封装 API,第二部分表示调完包后对调包代码的优化与 Scheduling,第三部分就是最下面的一些高效的 GPU kernel 实现、不同硬件后端的部署等等。 那么一个 Deep Learning 框架在 API 层需要包括什么内容呢?为什么大家要用框架而不是自己从头写呢? 下面这个图就回答了这个问题,现在的模型越来越大,实现起来需要注意的内容也就越来越多,如果每步都由我们自己来进行链式求导算梯度的话,可能就没有这么多转行深度学习的大哥了(
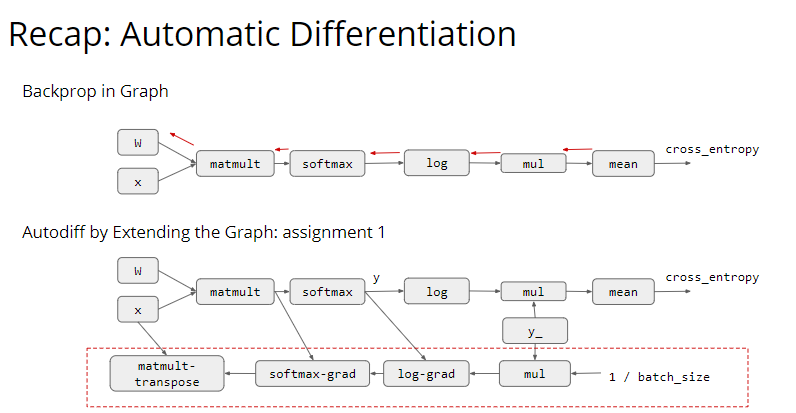
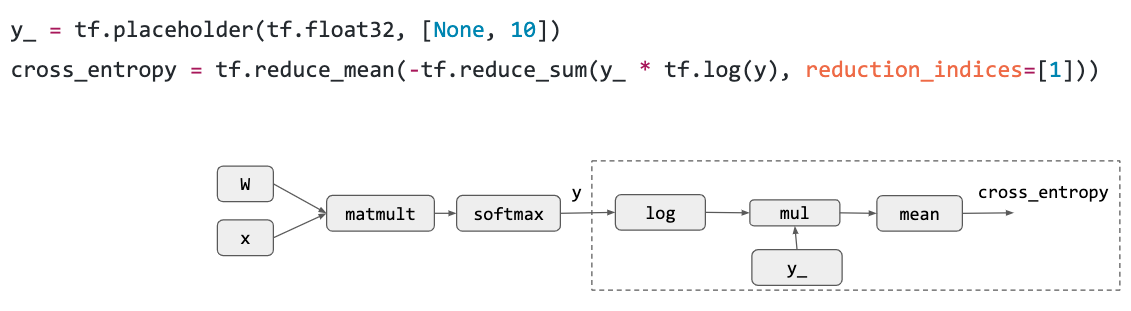
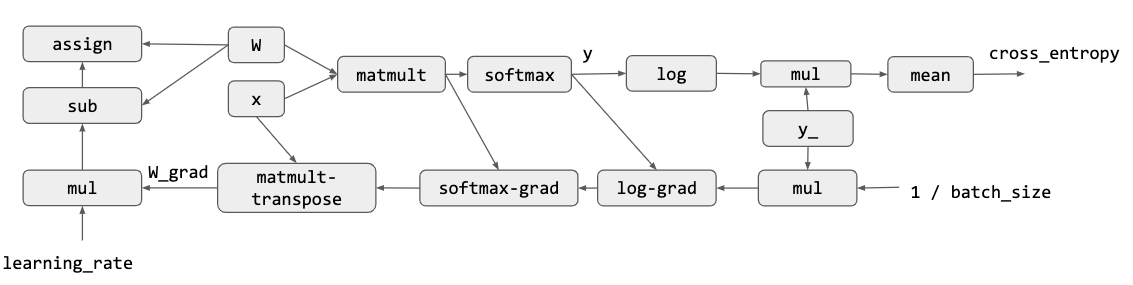
计算图是一个 Deep Learning 框架的基本概念,节点表示运算操作,边表示数据依赖,这里展示了一个最简单的 Logistic Regression 计算图实例: 首先是计算 loss 之前的前向传播,其实就是一个最简单的矩阵乘法加一个 softmax:
然后是将 softmax 输出的东西搞一个交叉熵作为 loss,相当于最大化 liklihood:
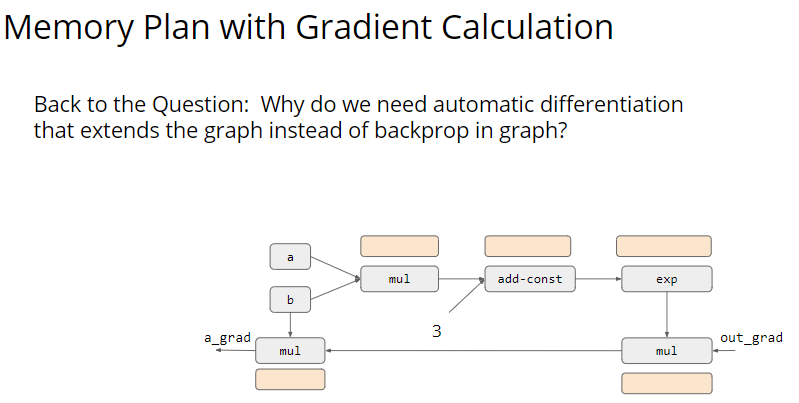
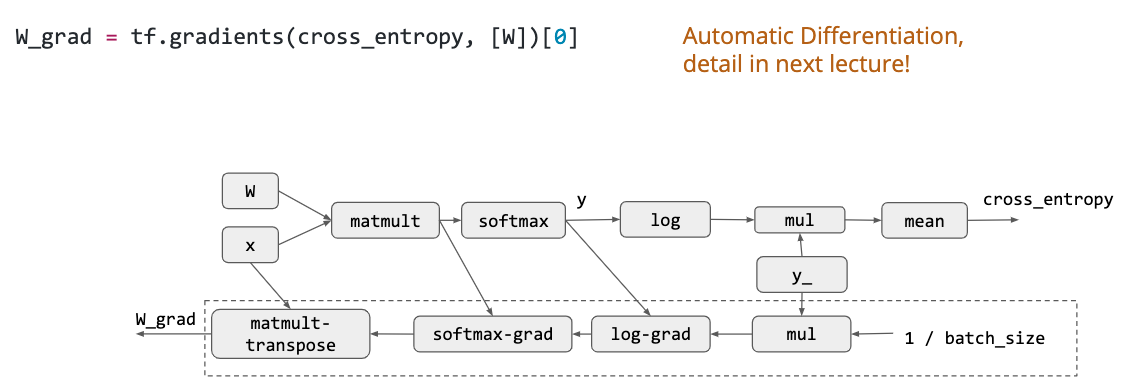
然后是自动微分:
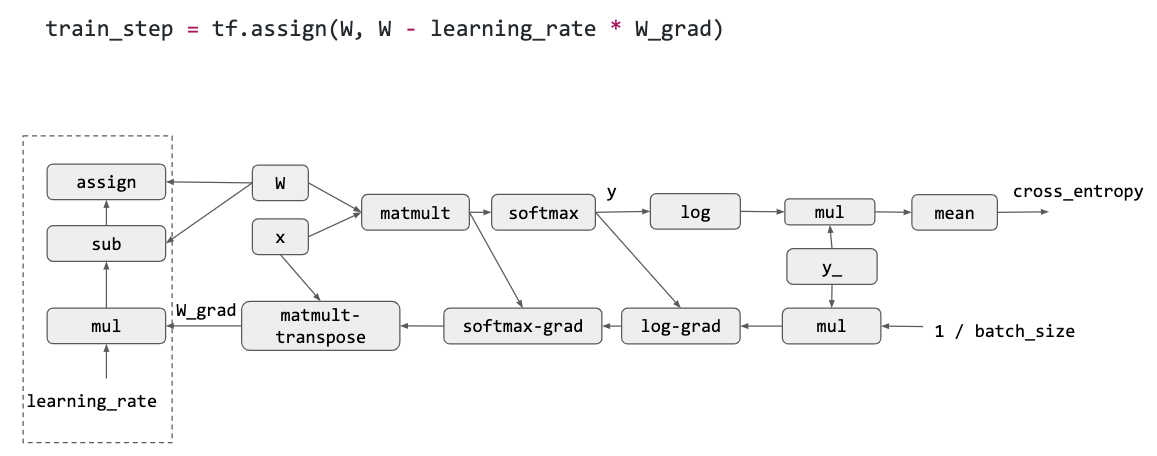
最后通过 SGD 来更新梯度:
结合上面的所有步骤,我们就得到了一个计算图:
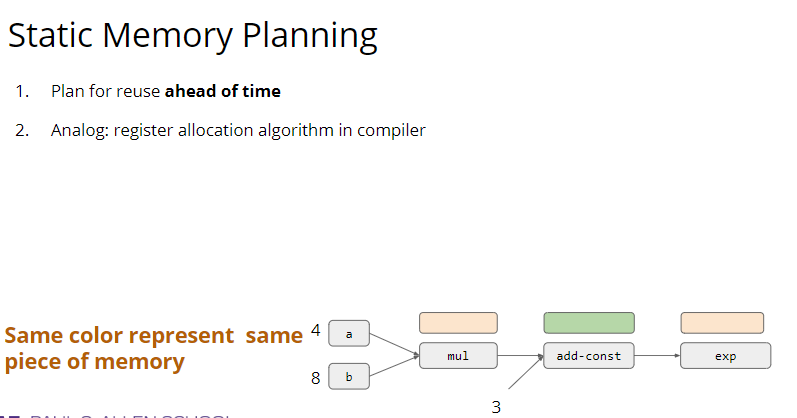
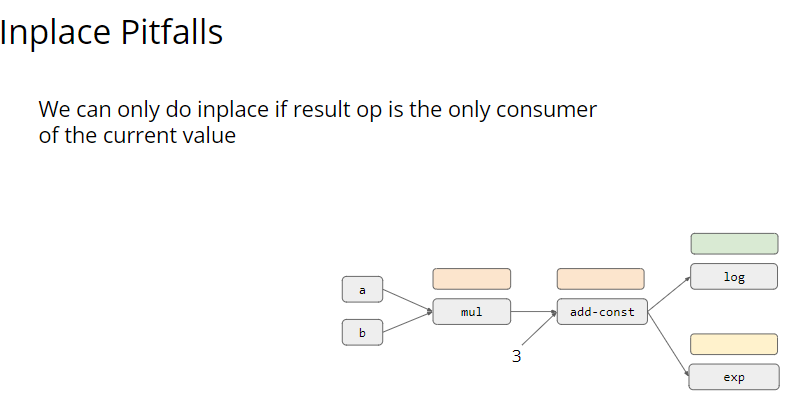
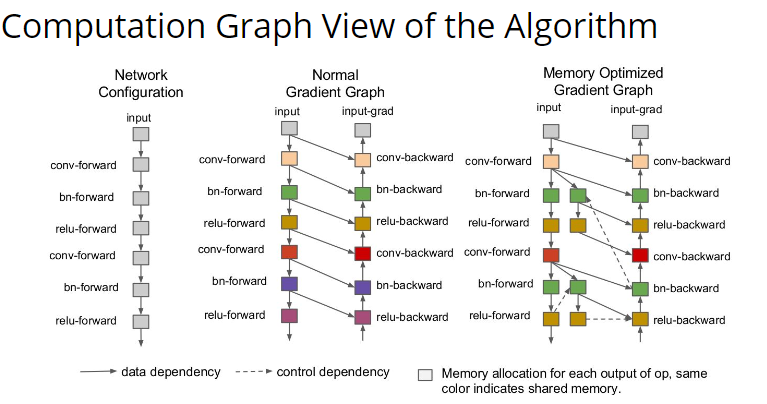
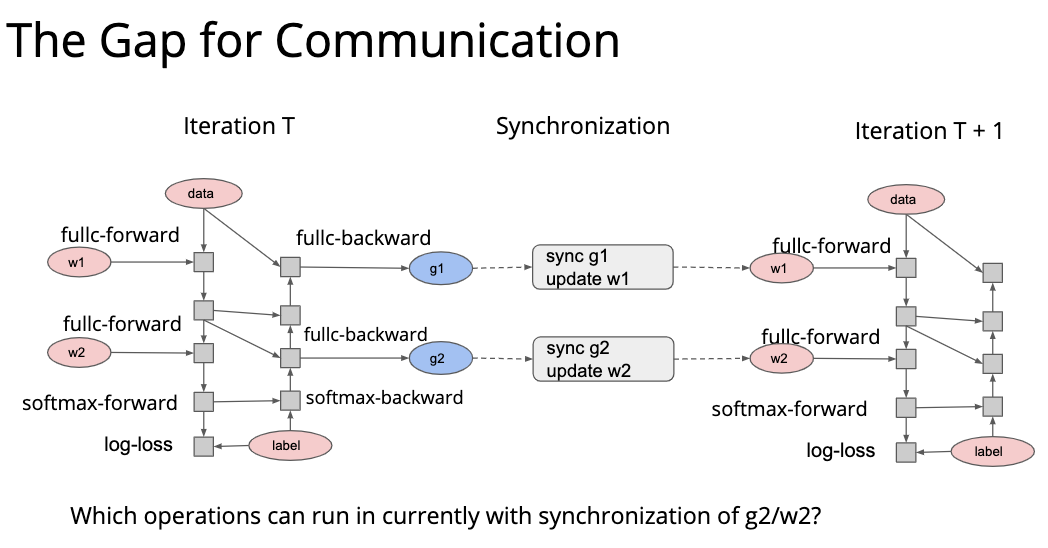
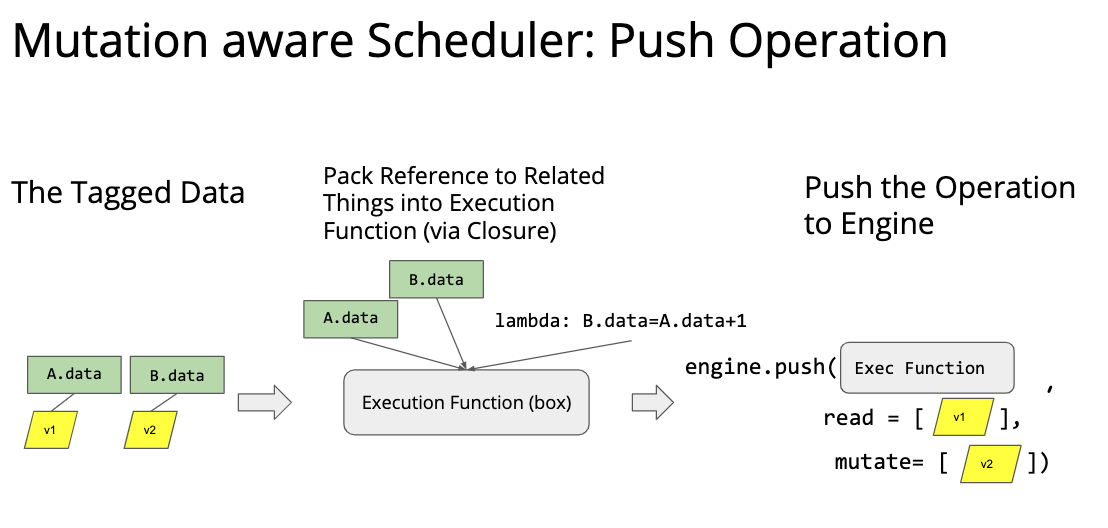
最上层的 API 做了最简单的介绍,下面就是中间的 System 部分,讲的是对计算图的优化和对计算的调度。 计算优化最简单的一种就是 memory 优化,比如增加 cache 利用率之类的。因为我们的代码通常跑在多个线程甚至多个计算设备上面,所以并行调度也是非常重要的。最简单的一种并行调度如下图,这是一个 mxnet 代码,因为计算 C 和计算 B 是完全独立的,所以这两个部分可以并行化。
TVM 就是为了解决这样的问题而诞生的,只要我们都搞成中间代码,全栈自动编译优化,这样 model 就可以非常简单的部署到不同的设备上了:
这门课将在接下来详细介绍 Deep Learning System 的三个部分。
Lecture 4: Backpropagation and Automatic Differentiation
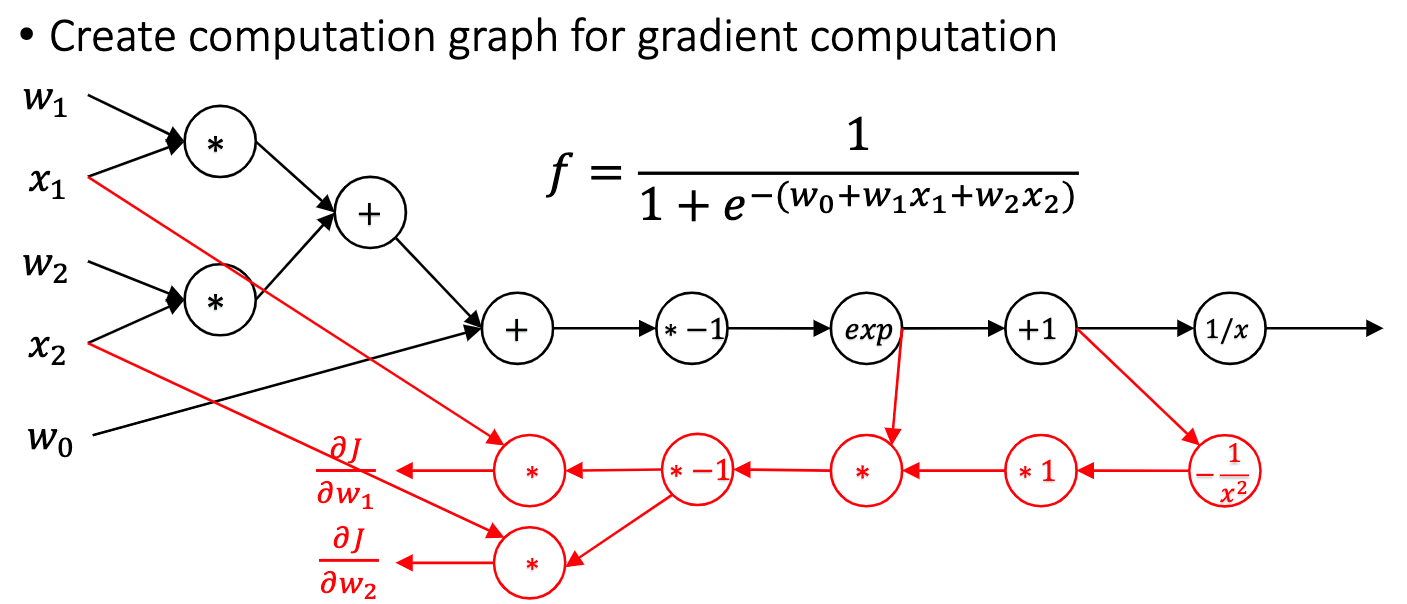
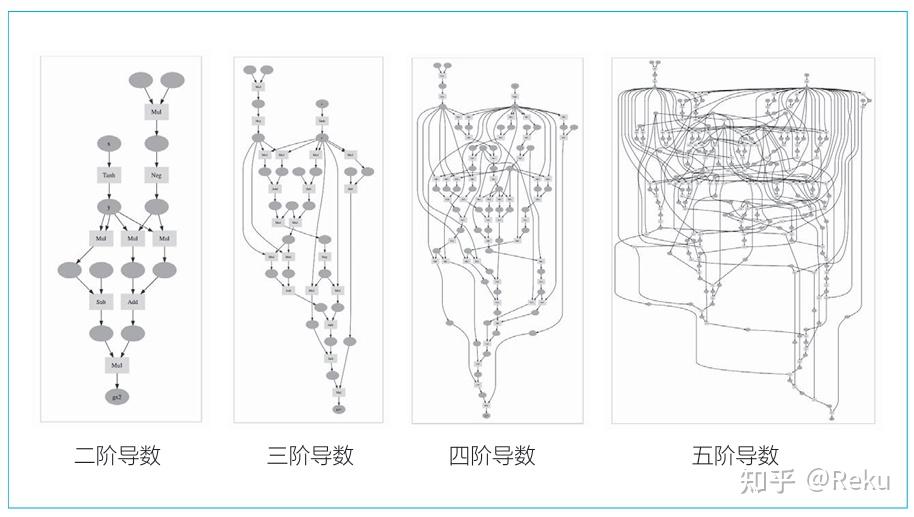
第四节课讲的是 Deep Learning 中的求导方式——Auto-Diff. 首先我们要了解现代计算机实现求导通常有哪些方式。 第一种叫做 Symbolic Differentiation,如图所示:
通过程序来维护整个求导的式子,然后把变量带入就得到最终的导数。这种做法的缺点在于表达式是一个很难维护的东西,最后要维护的东西就会越来越多。正常 Deep Learning 框架显然不应该选择这种求导方式... 第二种叫做 Numerical Differentiation,这种求导形式非常简单,看起来很适合计算机:
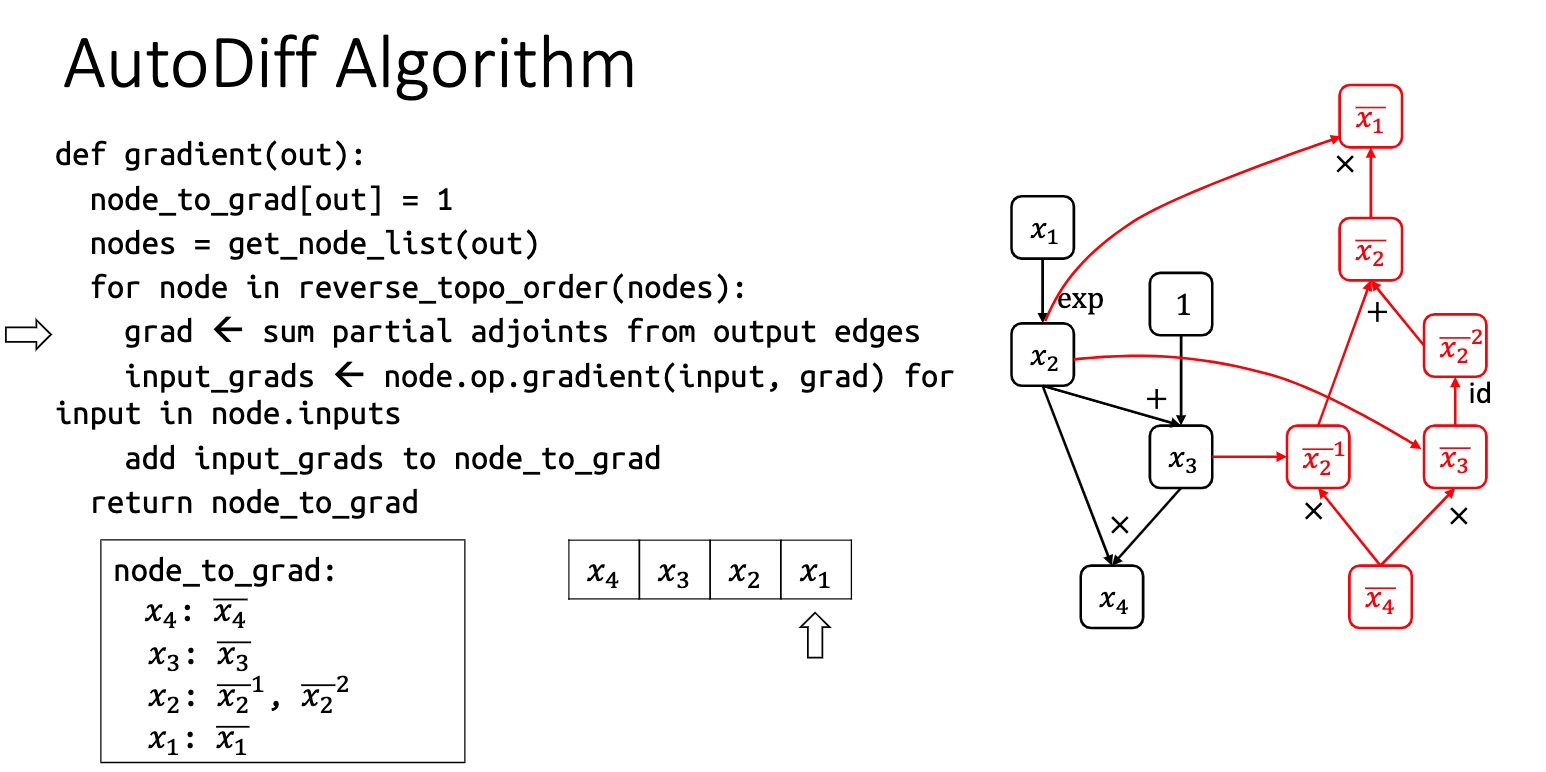
但是有个很关键的问题是,这种求导方法要进行两次正向传播,跑起来很慢,而且误差会比较大。但是因为其实现方式的简单,所以这是一个非常好的 grad check 工具。Ng 在 DL 专项里面也是用这种方式去进行 grad check 的。 第三种叫做 Backpropagation,现代 Deep Learning 的核心:
for node in topo_order: ifisinstance(node.op, PlaceholderOp): continue input_vals = [node_to_val_map[x] for x in node.inputs] res = node.op.compute(node, input_vals) ifisinstance(res, np.ndarray) == False: res = np.array(res) node_to_val_map[node] = res
这段是前向传播的部分,记录每个节点计算出来的结果。前向传播需要正向拓扑序。
1 2 3 4 5 6 7
for node in reverse_topo_order: grad = sum_node_list(node_to_output_grads_list[node]) node_to_output_grad[node] = grad input_grads = node.op.gradient(node, grad) for i inrange(len(node.inputs)): node_to_output_grads_list[node.inputs[i]] = node_to_output_grads_list.get(node.inputs[i], []) node_to_output_grads_list[node.inputs[i]].append(input_grads[i])
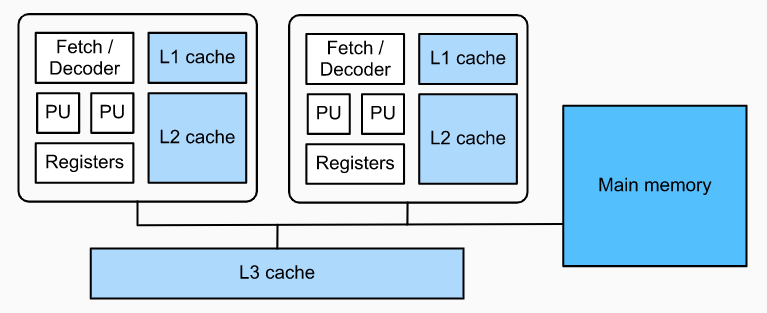
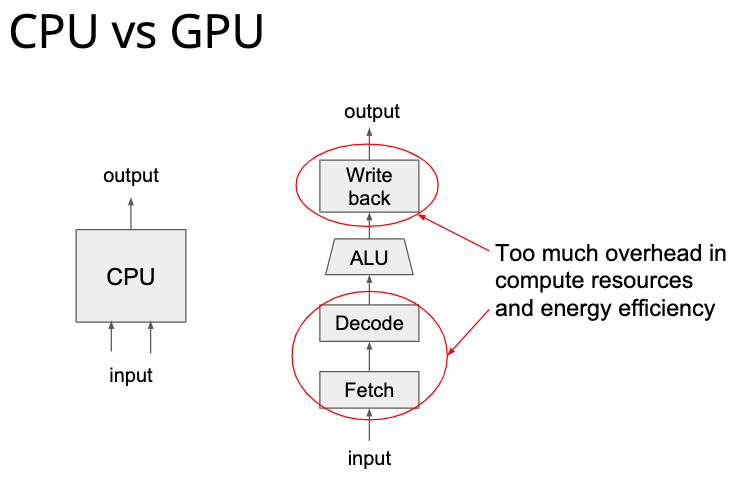
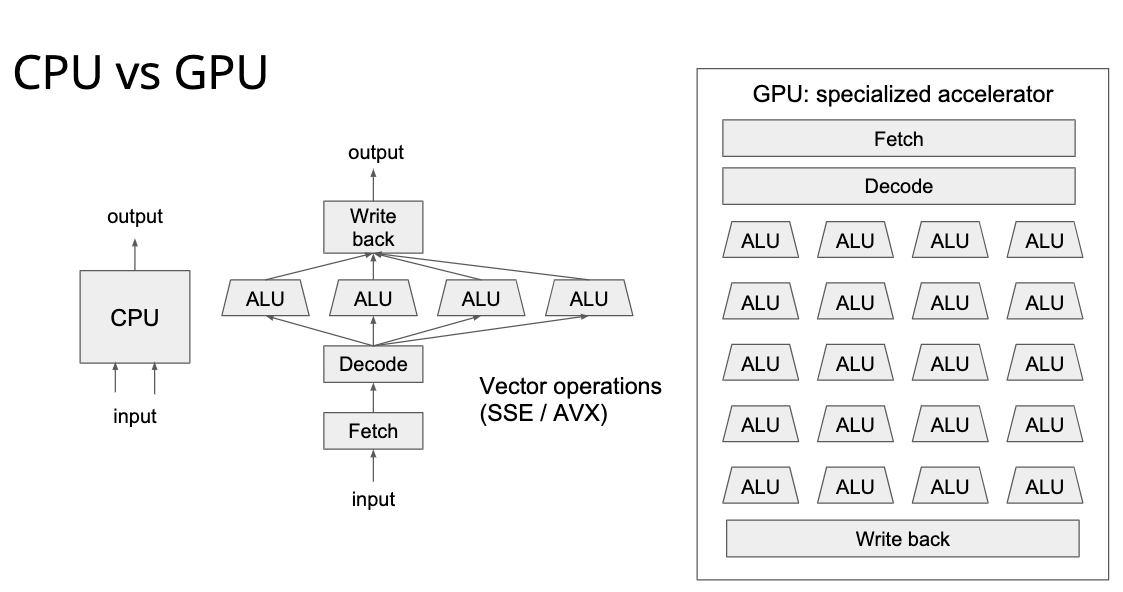
然后讲了 CUDA Programming Model,因为我完全不懂 CUDA 编程,所以后面的东西都是我瞎理解的,不一定对。 这个叫做 SIMT 的 Model 就是把几个 thread group 成一个 block,再把几个 block group 成一个 grid,block 可以以任何顺序在 GPU 上面调度。
然后是个最简单的 cuda 程序——vector add。过程非常简单,跟操作系统里面查页表差不多,这里通过 block 下标和 thread 下标可以得到向量加法的下标,然后每个线程都执行一样的代码就可以了。
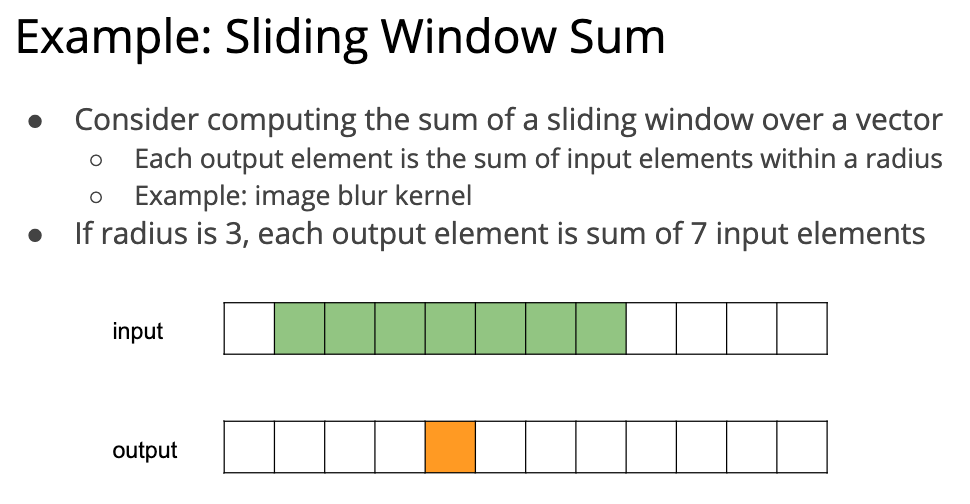
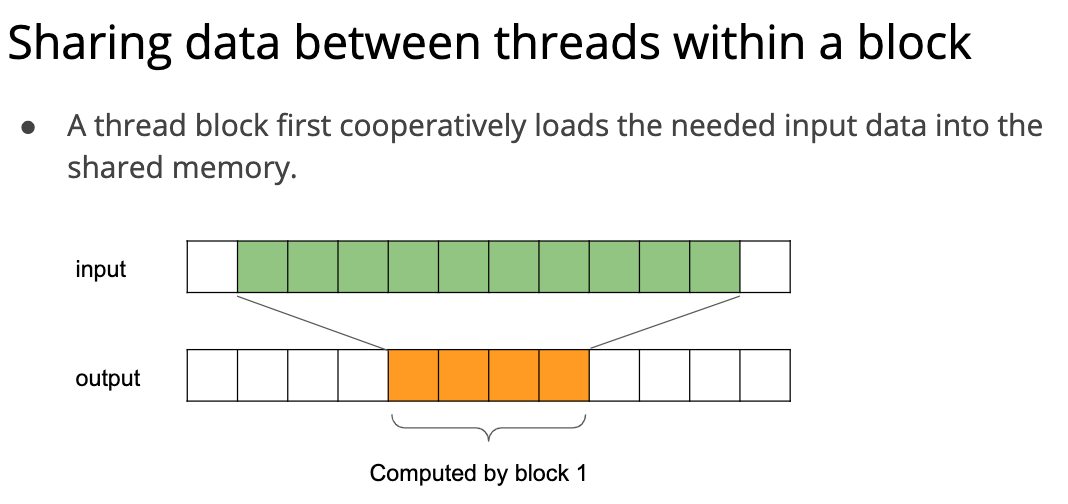
后面讲了一个窗口 sum 的例子,因为他图画的不太好,所以有点难以理解,我尽力理解了一下:
最简单的实现方式是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13
#define RADIUS 3 __global__ voidwindowSumNaiveKernel(constfloat* A, float* B, int n) { int out_index = blockDim.x * blockIdx.x + threadIdx.x; int in_index = out_index + RADIUS; if (out_index < n) { float sum = 0.; for (int i = -RADIUS; i <= RADIUS; ++i) { sum += A[in_index + i]; } B[out_index] = sum; } }
_-如何优化-Ulysses_img_0.jpg)


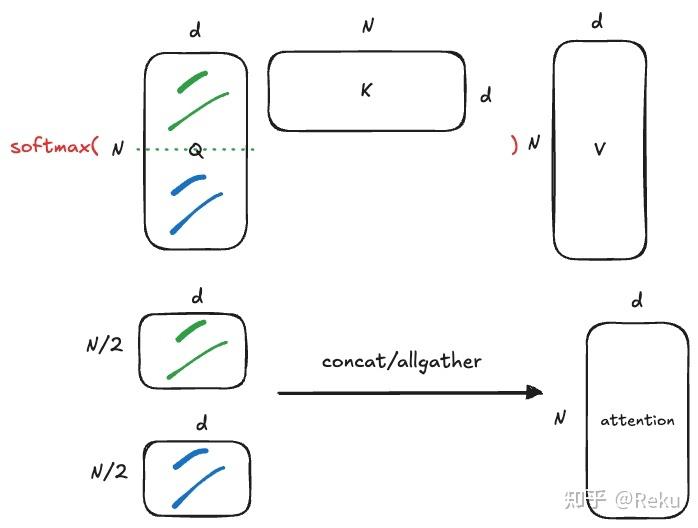
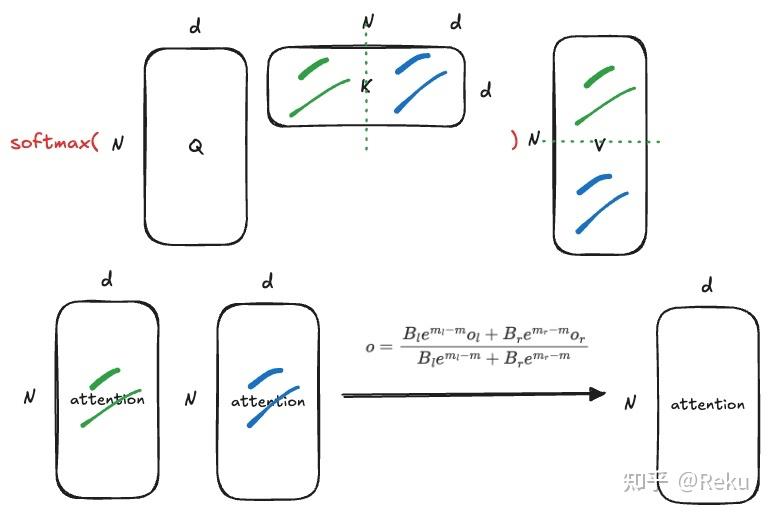
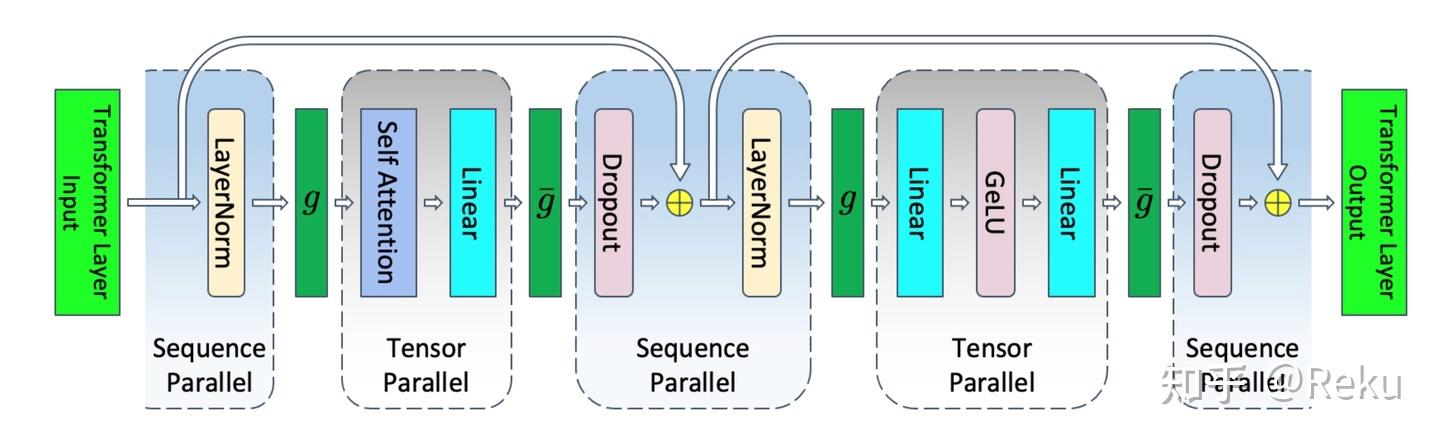
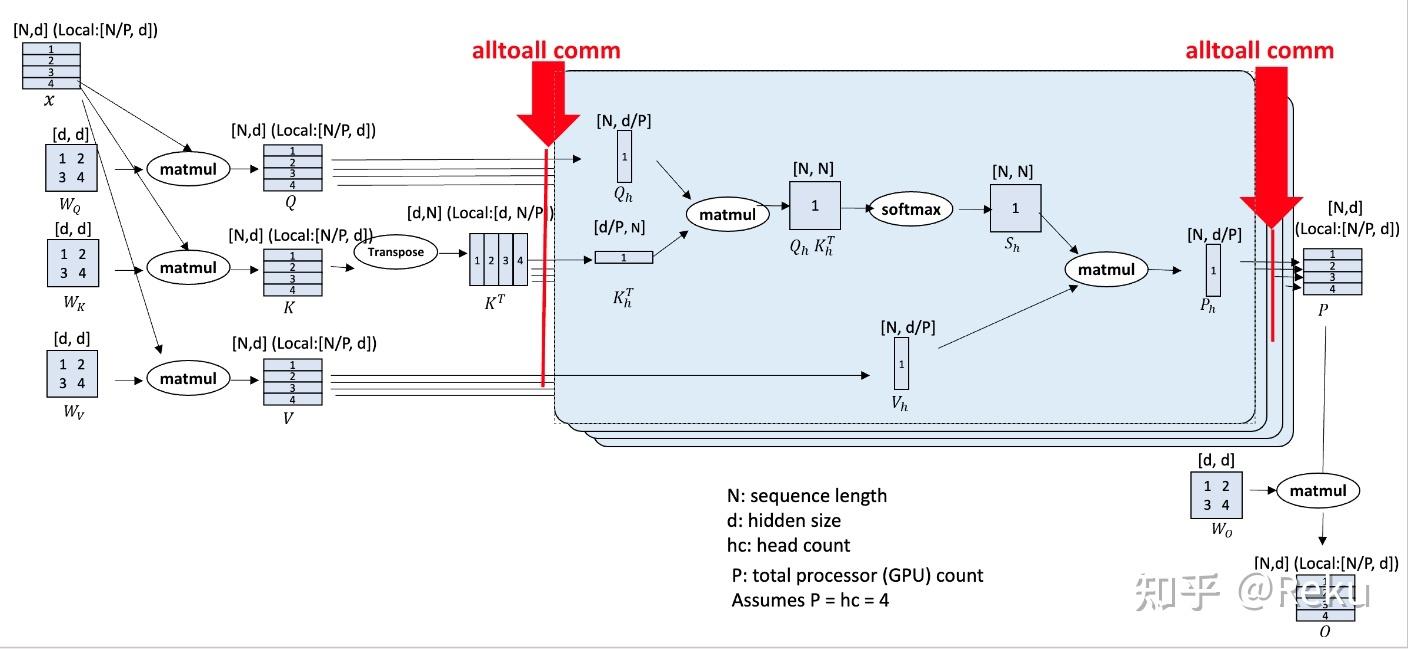


 深度学习入门2book.douban.com/subject/36303408/
深度学习入门2book.douban.com/subject/36303408/ Projects - Preferred Networks, Inc.www.preferred.jp/en/projects/
Projects - Preferred Networks, Inc.www.preferred.jp/en/projects/



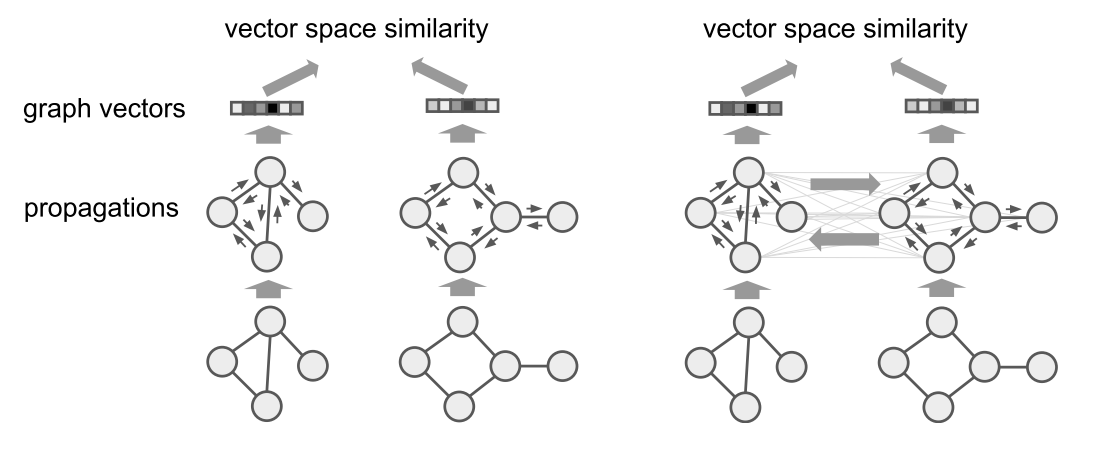
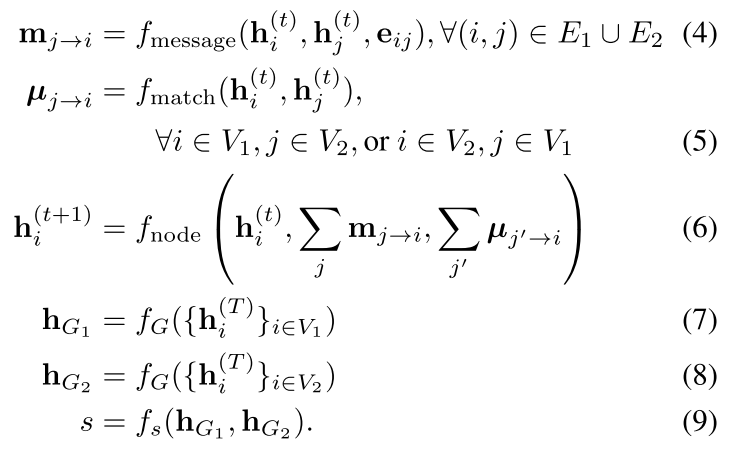
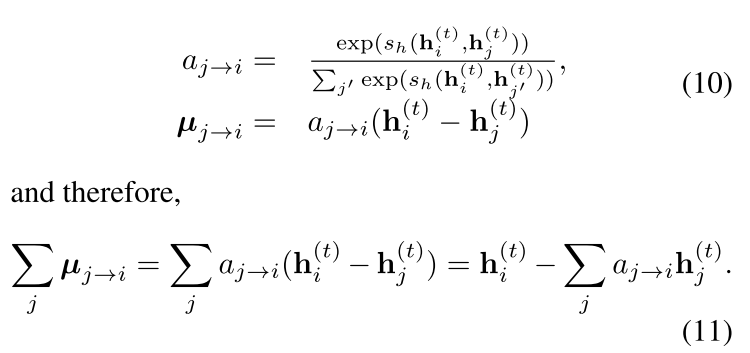
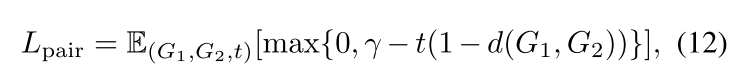
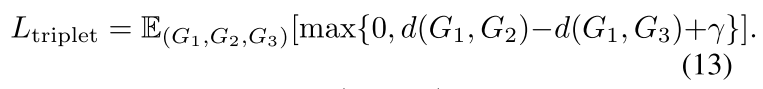
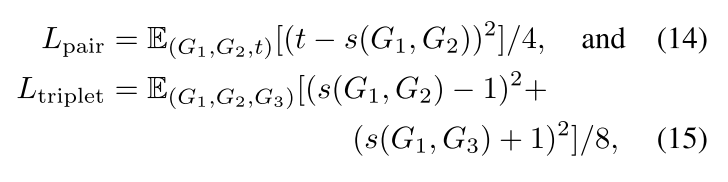 也可以按照上面的公式,用 Hamming 相似度来算,这样的好处是向量里面每一维度都是
也可以按照上面的公式,用 Hamming 相似度来算,这样的好处是向量里面每一维度都是